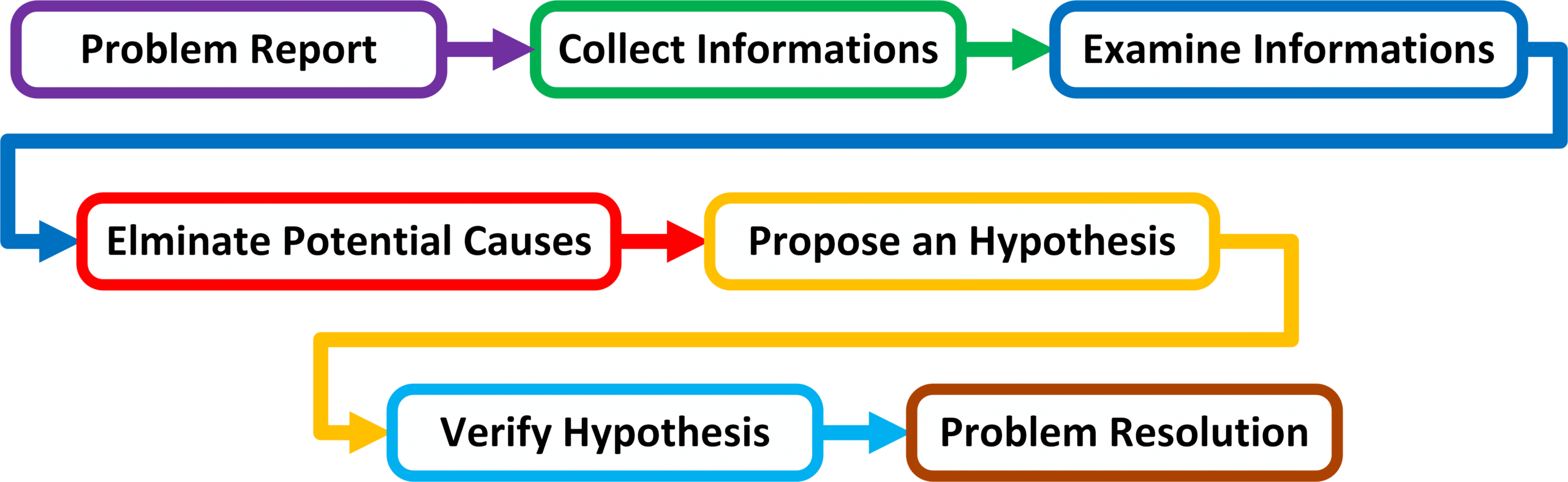
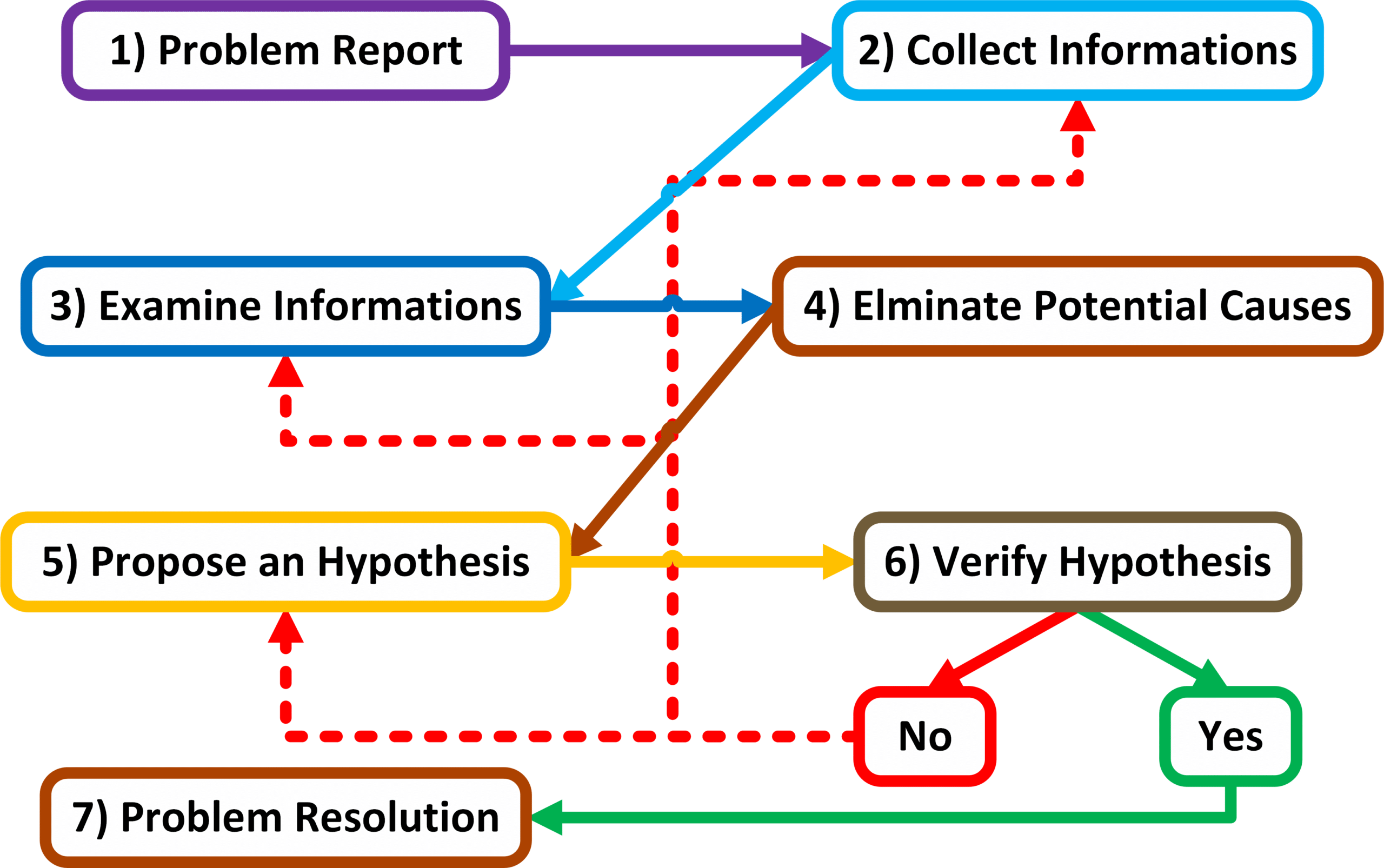
Narzędzia Troubleshooting-u
Metody uzyskiwania informacji
- Troubleshooting information collection – Informacje uzyskane podczas rozwiązywania bieżących problemów.
- Baseline information collection – Informacje uzyskane podczas normalnego funkcjonowania sieci.
- Network event information – Informacje uzyskane za pomocą wiadomości systemowych urządzań sieciowych.
Podstawowe narzędzia
- CLI – Umożliwia bieżące śledzenie aktywności danego urządzenia.
- GUI – W przejrzysty graficzny sposób przedstawia aktywność danego urządzenia.
- Recovery Tools – Umożliwia zapisywanie konfiguracji wielu urządzeń w bezpiecznym miejscu.
- Logging tools – Umożliwia śledzenie aktywności wielu urządzeń.
- NTP – Określa czas wystąpienia danego zdarzenia.
- NetFlow – Monitoruje aktywność sieciową interfejsów.
- IP SLA – Monitoruję osiągalność wyznaczonego adresu IP.
- SNMP – Umożliwia zaawansowane śledzenie aktywności wielu urządzeń.
- Cisco Support – Prowadzi wsparci za pomocą serwisów CMS bądź TAC.
Komenda Ping i Traceroute
Możliwe przyczyny braku odpowiedzi na pakiet ICPM
- Lista ACL blikująca ruch sieciowy po adresach IP
czy portach TCP, UDP (List ACL nie może filtrować ruchu wychodzącego,
zainicjonowanego przez urządzenie, na którym sama powstała jak i funkcjonuje).
- Funkcja „PortSecurity” włączona na przełączniku
w celu filtrowania np. adresów MAC, może wyłączyć interfejs blokując tym samym
cały ruch na niego przychodzący bądź z niego wychodzący.
- Złe ustawienia trasy domyślnej w tablicy
routingu, mogą kierować nadpływający ruch sieciowy w złym kierunku.
- Błędna adresacja urządzeń, może spowodować
przypisanie złych adresów IP należących do innej sieci.
- Problemy na warstwie drugiej oraz pierwszej
modelu OSI, mogą zablokować połączenie sieciowe.
- Błędna konfiguracja serwera DHCP, mogła
spowodować przypisanie błędnego adresu IP, maski czy adresu bramy D.
- Wadliwa konfiguracja połączenia Trunk-owego,
mogła wpłynąć na gubienie pakietów pomiędzy przełącznikiem a ruterem.
Jeżeli pakiet ICPM dotrze do bramy domyślnej, to można założyć, że
- Adres IP bramy domyślnej jest osiągalny z poziomu hosta.
- Sieć lan przepuszcza ruch unicast pomiędzy hostem a bramą domyślną.
- Przełącznik uczy się adresów MAC nadchodzących na jego interfejsy, w ramkach Ethernetowych.
- Zaszła wymiana danych pomiędzy hostem a bramą domyślną, mająca na celu obopólną nauką adresów MAC za pomocą protokołu APR (Address Resolution Protocol).
Zasada działania komendy Traceroute
- Host wysyła pakiet ICMP z ustawioną wartością
TTL na 1.
- Ruter otrzymuje pakiet ICMP, zmniejszając jogo
wartość TTL na 0.
- Ruter uznaje, że pakiet przekroczył maksymalną
drogę a jego sieć docelowa jest nieosiągalną.
- Ruter odsyła pakiet ICMP z informacją o
nieosiągalności sieci docelowej.
- Host wysyła pakiet ICMP, z wartością TTL
zwiększoną o 1.
Wysyłanie wiadomości ICMP
# ping adres-IP [size 36-18024(100)(Datagram size) / repeat 1-2147483647(5) / timeout 0-3600(2) / source {adres-IP / interfejs} / df-bit(Don’t fragment bit)]
Xxx
Hardware Troubleshooting
Komendy SHOW
# show processes cpu
Wyświetla poziom utylizacji procesora CPU.
# show memory
Wyświetla zsumaryzowane informacje na temat procesów przetrzymywanych w pamięci.
# show interfaces interfejs
Wyświetla informacje dotyczące danego interfejsu.
# show platform
Wyświetla szczegółowe informacje na temat danego urządzenia.
Zaawansowana filtracja komend SHOW
Komendy SHOW
# show komenda | begin wyrażenie
Wyświetla wydruk komendy Show zaczynając do linii zawierającej dane wyrażenie.
# show komenda | count wyrażenie
Wyświetla ilość linii komendy Show zawierających dane wyrażenie.
# show komenda | exclude wyrażenie
Wyświetla linie komendy Show nie zawierające danego wyrażenia.
# show komenda | include wyrażenie
Wyświetla linie komendy Show zawierające dane wyrażenie.
# show komenda | redirect zasób
Przekierowuje wydruk komendy show na dany zasób (Docelowy plik nie musi istnieć).
# show komenda | append zasób
Przekierowuje wydruk komendy show na dany zasób (Docelowy plik musi istnieć).
# show komenda | tee zasób
Przesyła wydruk komendy show na dany zasób.
# show komenda | section sekcja
Wyświetla określoną sekcje komendy Show.
Unix-owe komendy w systemie Cisco IOS
(config)# shell processing full
Aktywuje dostęp do komend unix-owych.
# show komenda-show | grep fraza
Wyświetla wiersz zawierający podaną frazę.
# show komenda-show | grep fraza | wc -l
Wyświetla ilość wierszy zawierających daną frazę.
Pozostałe tematy związane z Troubleshooting-iem
Podstawy sieci komputerowych
Warstwy modelu OSI
Bezpieczeństwo sieci
Troubleshooting