Proces Troubleshooting-u stanowi proces rozwiązywania problemów sieciowych.
Prosta metoda rozwiązywania problemów
Problem Report – Szczegółowe zdefiniowanie problemu.
ProblemDiagnosis – Określenie prawdopodobnej przyczyny (Postawienie hipotezy)
ProblemResolution – Podjęcie próby naprawy występującego problemu.
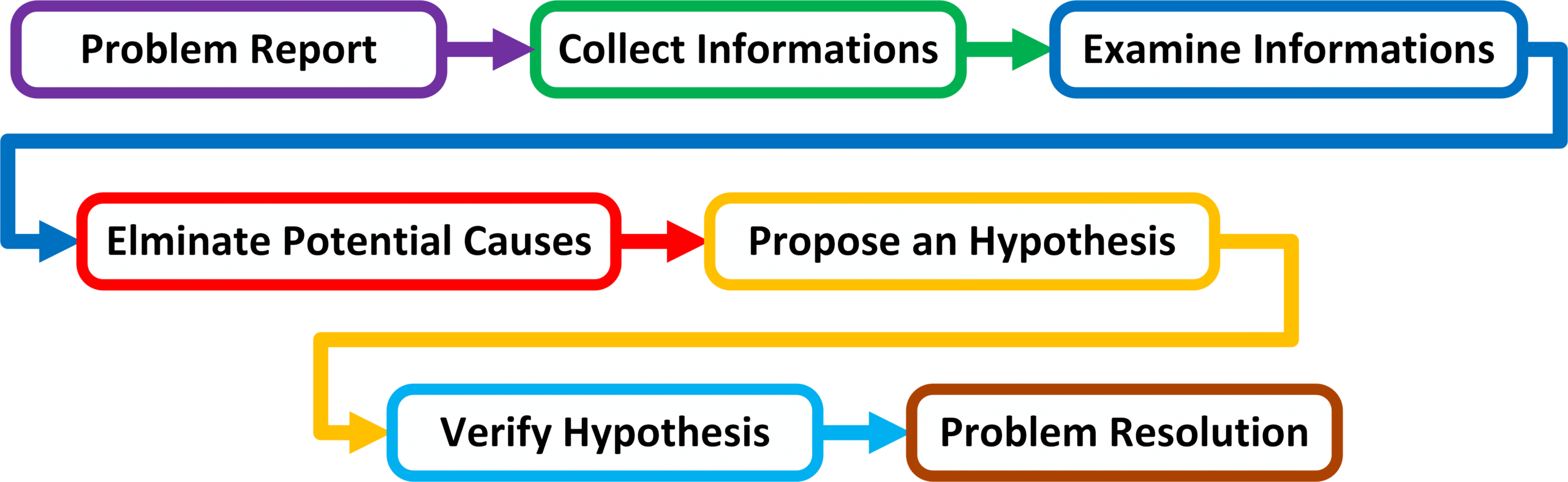
Złożona metoda rozwiązywania problemów
Złożona metoda rozwiązywania problemów rozbija punkt „Problem Diagnosis” przedstawiony w powyższym diagramie na pięć oddzielnych punktów, definiując tym samym siedem kroków w rozwiązywaniu problemów sieciowych.
Złożona metoda rozwiązywania problemów
Problem Report – Szczegółowe zdefiniowanie problemu.
Collect Informations – Zebranie dodatkowych informacji za pomocą dedykowanych narzędzi sieciowych czy rozmów z użytkownikami dotkniętych danym problemem.
Examine Collect Informations – Porównanie między sobą informacji zebranych z rożnych źródeł.
Elminate Potential Causes – Eliminacja prawdopodobnych przyczyn powstania problemu na podstawie zebranych informacji z punktu drugiego oraz z punktu trzeciego.
Propose an Hypothesis – Wysnucie hipotezy co do przyczyny powstania problemu na podstawie zebranych informacji.
Verify Hypothesis – Sprawdzenie wysnutej hipotezy za pomocą dedykowanych narzędzi sieciowych.
Problem Resolution – Podjęcie próby naprawy występującego problemu.
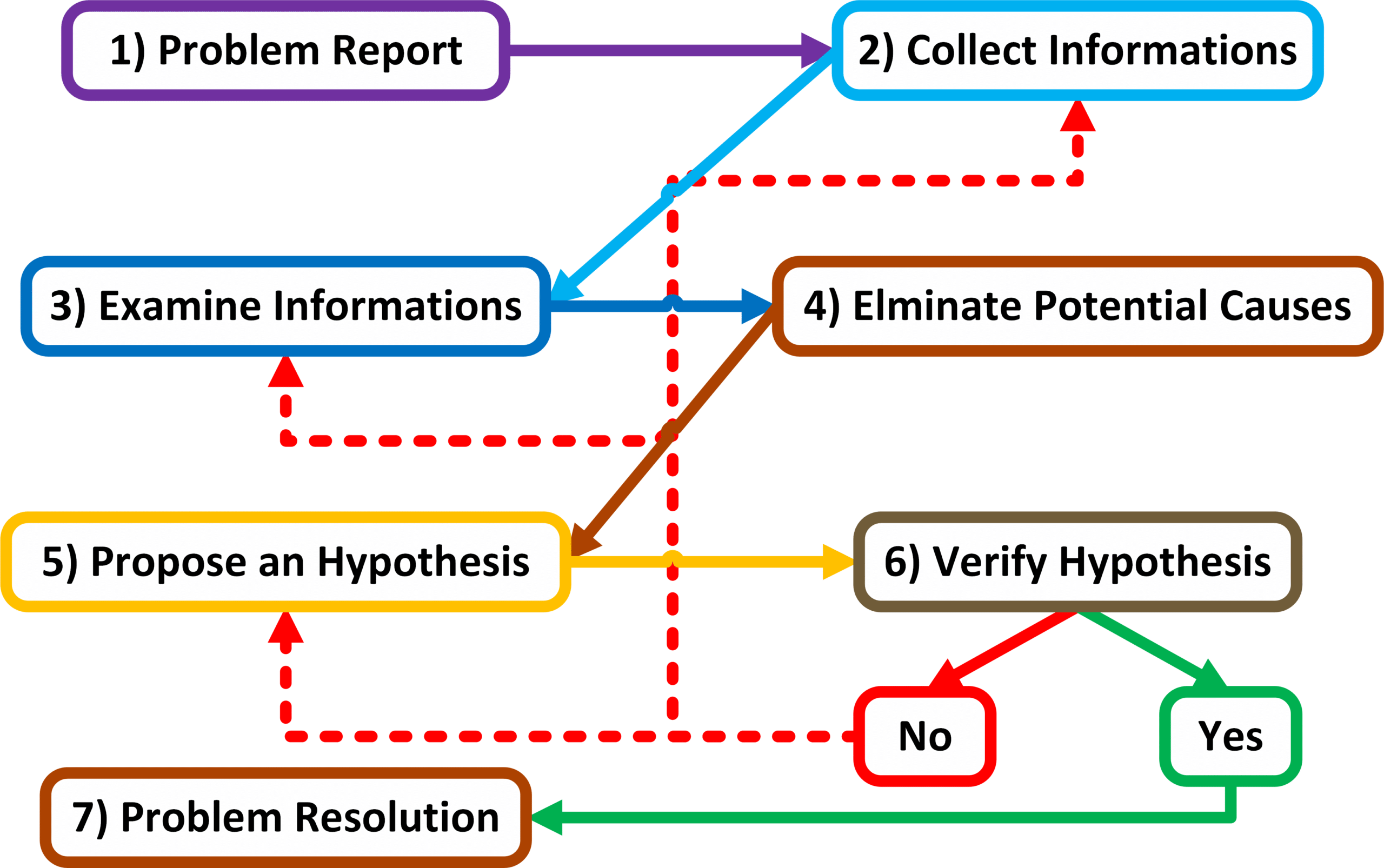
Podejście strukturalne
Strukturalne podejście do rozwiązywania problemów sieciowych, powinno być dostosowywane do panującej sytuacji danego problemu. Struktura ta umożliwia pominięcie niektórych kroków sytuacji w której umożliwi to przyspieszenie samego procesu.
Strukturalny model rozwiązywania problemów sieciowych
Problem
Report
Szczegółowe zdefiniowanie problemu wymaga od administratora zebrania podstawowych danych od użytkownika zgłaszającego problem. W punkcie tym należy określić jakiego rodzaju jest to problem oraz kto powinien się nim zająć.
Przykładowo użytkownik zgłasza problem z brakiem dostępu do Internetu, po sprawdzeniu okazuje się że użytkownikowi wyskakuje „error 404” przy czym komunikacja z wewnętrznym serwerem http działa poprawnie.
Collect
Informations
Zebranie dodatkowych informacji za pomocą dedykowanych narzędzi sieciowych czy rozmów z użytkownikami dotkniętych danym problemem, wymaga od administratora wiedzy na temat zasad działania zasobów co do których wystąpił problem. Wiedza ta umożliwia oszczędzenie czasu, ponieważ administrator skupia się na zebraniu informacji z urządzeń oraz od osób które w sposób bezpośredni bądź pośredni związane z procesem działania danego zasobu.
Przykładowo problem związany z dostępnością serwerem FTP, może wynikać z błędnej konfiguracji lokalnego programu FTP a nie koniecznie dotyczyć komunikacji komputera z serwerem tudzież samego serwera FTP. Wiedząc to administrator wpierw skupi się na sprawdzeniu konfiguracji lokalnego urządzenia, zamiast marnować czas na weryfikacje ustawień sieciowych.
Examine
Informations
Po zebraniu niezbędnych informacji na temat danego problemu, takich jak logging-i, wydruki komend „show” oraz „debug”, pakiety przechwycone przez programy śledzące typu „Sniffer” czy wyniki operacji „ping” jak i „traceroute”. Administrator powinien zidentyfikować wskaźniki wskazujące na przyczynę powstawania problemu jak i dowody wspomagające dalszą weryfikację. Wykonując to zadanie administrator powinien porównać ze sobą dwie wartości: to jak konfiguracja sieci wygląda z tym jak wyglądać powinna.
W tym punkcie procesu rozwiązywania problemów sieciowych istotną rolę gra aktualna dokumentacja sieciowa.
Przykładowo użytkownik może być nie świadomy że komunikacja z serwerem FTP wymaga posiadania dodatkowej aplikacji, zweryfikowanie tego z dokumentacją uwidacznia przyczynę powstania danego problemu.
Elminate
Potential Causes
Eliminacja prawdopodobnych przyczyn powstania problemu na podstawie zebranych informacji.
Propose
an Hypothesis
Po wyborze najbardziej prawdopodobnych przyczyn powstania problemu, na podstawie zabranych informacji, administrator może skupić się na pozostałych teoriach formując na ich podstawie hipotezę.
Verify
Hypothesis
Po określeniu najbardziej prawdopodobnej hipotezy, należy ją zweryfikować a następnie przygotować plan naprawy danego problemu. Może być to rozwiązanie zarówno stałe jak i tymczasowe.
Problem
Resolution
Podjęcie próby naprawy występującego problemu.
Popularne metody Troubleshooting-u
Metody rozwiązywania problemów
The top-down method (7 ->1) – Metoda rozpoczynająca proces troubleshooting-u od warstwy aplikacji (7) a kończąca na warstwie fizycznej (1).
The bottom-up method (1 ->7) – Metoda rozpoczynająca proces troubleshooting-u od warstwy fizycznej (1) a kończąca na warstwie aplikacji (7).
The divide-and-conquer method (1 <- 3 -> 7) – Metoda rozpoczynająca proces troubleshooting-u od warstwy trzeciej (3) a następnie idąca w górę do warstwy aplikacji (7) bądź w dół od warstwy fizycznej (1), w zależności od osiągniętego rezultatu. Jeżeli np. komenda Ping nie osiągnie zamierzonego celu, administrator uzna że błąd dotyczy warstw niższych.
Following the traffic path – Metoda rozpoczynająca proces troubleshooting-u od weryfikacji połączenia pomiędzy hostem zgłaszającym problem a najbliższym urządzeniem sieciowych. W kolejnym kroku weryfikacji podlega następne urządzenie stojące na drodze od hosta do celu danej transmisji.
Comparing configurations – Metoda rozpoczynająca proces troubleshooting-u od porównania konfiguracji bieżącej z ostatnią znaną i wypełni sprawną konfiguracją.
Component swapping – Metoda rozpoczynająca proces troubleshooting-u od wymiany komponentów. Przykładowo wymianie takiej może podlegać kabel Ethernet-owy, pojedynczy moduł rutera bądź całe urządzenie sieciowe.
Konserwacja sieci (Maintenance)
Definicja procesu konserwacji sieci
Proces konserwacji pozwala utrzymać sieć w stanie spełniającym wymogi założeń biznesowych, związanych z funkcjonowaniem i dostępnością sieci. Przykładowe czynności zaliczane do procesu konserwacji są następujące:
Instalacja i konfiguracja urządzeń sieciowych.
Rozwiązywanie problemów (Troubleshooting).
Monitorowanie i zwiększanie wydajności sieci.
Tworzenie dokumentacji sieci jak i zmian w niej dokonywanych.
Sprawdzanie sieci pod kontem zgodności z prawem oraz standardami firmowymi.
Zabezpieczanie sieci przed zewnętrznymi jak i wewnętrznymi zagrożeniami.
Tworzenie kopi zapasowych.
Proaktywne (Proactive) & Reaktywne (Reactive) podejście do konserwacji
sieci
Podejście do procesu konserwacji sieci może być podjęte na dwa sposoby:
Interrupt-driven Tasks – Obejmuje proces rozwiązywania problemów w miarę ich zgłaszania.
Sructured Tasks – Obejmuje proces rozwiązywania problemów w sposób zaplanowany. Dzięki czemu możliwe staje się zapobieganie awariom, zanim staną się one poważnym problemem dla całej infrastruktury. Podejście to odnosi się również do planowanych inwestycji, w wymianę istniejącego jak i zakup nowego sprzętu oraz oprogramowania.
W celu uproszczenia procesu konserwacji sieci, stworzono wiele ustandaryzowanych procedur takich jak:
Poszczególne elementy procesu konserwacji sieci wyglądają następująco:
Fault Management – Za pomocą narzędzi monitorujących jak i zbierających dane na temat stanu infrastruktury sieciowej, nadzoruje czy utylizacja urządzeń oraz przepustowość linków nie przekracza dopuszczalnej normy.
Configuration Management – Wymaga ciągłej aktualizacji zmian zachodzących w infrastrukturze sieciowej związanych z wymianą urządzeń bądź ich oprogramowania. Proces ten odnosi się również do bieżącej aktualizacji narzędzi monitorujących i zbierających dane na temat stanu infrastruktury sieciowej.
Accounting Management– Nadzorowanie zmian zachodzących w infrastrukturze sieciowej.
Performance Management – Monitorowanie przepustowości połączeń lokalnych LAN oraz zewnętrznych WAN, z uwzględnieniem implementacji jak i nadzorowania funkcji kolejkowania QoS.
Security Management – Wdrażanie jak i monitorowanie zapór ogniowych (Firewall), wirtualnych połączeń prywatnych VPN, systemów prewencyjnych IPS, zabezpieczania dostępu za pomocą funkcji AAA czy nadzorowania polis bezpieczeństwa takich lak np. listy ACL.
Metody konserwacji sieci
Rutynowe zadania konserwacyjne
Rutynowe zadania konserwacyjne stanowią nierozłączną część każdej odpowiednio zaplanowanej infrastruktury sieciowej, są to zadania wykonywane regularnie co godzinie, dzień, tydzień, miesiąc czy rok bądź też nieregularne takie jak dodawanie nowych użytkowników. Przykładowe zadania związane z rutynową konserwacją mogą być następujące:
Configuration changes – Dodawanie nowych użytkowników, urządzeń bądź oprogramowania. Dokonywanie zmian związanych z relokacją obecnych zasobów (Użytkowników, urządzeń) wraz związaną z tym rekonfiguracją systemów.
Replacement of older or failed hardware – Wymiana starych bądź uszkodzonych urządzeń.
Scheduled backup – Tworzenie kopi zapasowych konfiguracji, logging-ów zebranych z urządzeń sieciowych.
Monitoring network performance – Monitorowanie jak i zbieranie informacji na temat utylizacji urządzeń oraz przepustowości linków. Co może uprościć proces troubleshooting-u jak i pomóc w planowaniu nowych inwestycji.
Planowanie zadań konserwacyjnych
Kto zatwierdza zmiany dokonywane w infrastrukturze sieciowej.
Jakie zadania powinny być wykonywane jedynie w oknie czasowym przeznaczonym na zadania konserwacyjne.
Jakie procedury obowiązują podczas przeprowadzania zadań konserwacyjnych.
Jakie kryteria określają sukces bądź porażkę przeprowadzonych zadań konserwacyjnych.
W jaki sposób będą dokumentowane zmiany zachodzące w infrastrukturze sieciowej.
Jakie narzędzia pozwolą przywrócić poprzednią działającą konfiguracje w przypadku niepowodzenia w wdrażaniu nowych rozwiązań bądź aktualizacji obecnej infrastruktury sieciowej.
Prowadzenie dokumentacji sieciowej
Dokumentacja infrastruktury sieciowej
Tworzenie jak i utrzymywanie bieżącej dokumentacji infrastruktury sieciowej ułatwia proces troubleshooting-u, ponieważ administrator w łatwy sposób może rozeznać się w konfiguracji sieci porównując stan obecny z założeniami.
Dokumentacja infrastruktury sieciowej może zwierać fizyczną (Physical) i logiczną (Logical) topologię sieci, konfiguracje poszczególnych urządzeń, procedury zmiany bieżącej konfiguracji, kontakt z osobami odpowiedzialnymi za daną część sieci czy wykaz dokonywanych zmian. Podsumowując dokumentacja infrastruktury sieciowej może zwierać:
Topologię logiczną (Logical Topology).
Topologię fizyczną (Physical Topology).
Listę połączeń pomiędzy urządzeniami.
Inwentarz urządzeń sieciowych.
Spis adresacji sieciowej.
Informacje na temat konfiguracji.
Plany założeń infrastruktury sieciowej.
Przywracanie sieci po awarii
Przywrócenie pełnej funkcjonalności sieci po awarii urządzeń sieciowych, może być dokonane za pomocą:
Z duplikowanego wyposażenia (Hardware) znajdującego się w lokalnym magazynie.
Zapasowego oprogramowania przetrzymywanego na lokalnych serwerach.
Kopi zapasowych (Konfiguracji) pobranych z urządzeń sieciowych.

Dodaj komentarz