Zapisuje zrzut pamięci urządzenia sieciowego (Core dump) wraz z czasem wystąpienia błędu krytycznego. W następstwie którego urządzenie te zostanie zresetowane. Na wskazany w komendzie adres IP zostanie wysłany zapisany zrzut pamięci wraz z datą (Za pomocą protokołu TFTP).
Błędy krytyczne (zrzut FTP)
(config)#ip ftp username login
Definiuje login użytkownika, wykorzystywany przez protokół FTP.
(config)#ip ftp password hasło
Definiuje hasło użytkownika, wykorzystywane przez protokół FTP.
(config)#exception protocol ftp
Wykonuje zrzut pamięci urządzenia sieciowego (Core dump), przy wykorzystaniu protokołu FTP.
IP SLA – Monitoruję osiągalność wyznaczonego adresu IP.
SNMP – Umożliwia zaawansowane śledzenie aktywności wielu urządzeń.
Cisco Support– Prowadzi wsparci za pomocą serwisów CMS bądź TAC.
Komenda Ping i Traceroute
Możliwe przyczyny braku odpowiedzi na pakiet ICPM
Lista ACL blikująca ruch sieciowy po adresach IP
czy portach TCP, UDP (List ACL nie może filtrować ruchu wychodzącego,
zainicjonowanego przez urządzenie, na którym sama powstała jak i funkcjonuje).
Funkcja „PortSecurity” włączona na przełączniku
w celu filtrowania np. adresów MAC, może wyłączyć interfejs blokując tym samym
cały ruch na niego przychodzący bądź z niego wychodzący.
Złe ustawienia trasy domyślnej w tablicy
routingu, mogą kierować nadpływający ruch sieciowy w złym kierunku.
Błędna adresacja urządzeń, może spowodować
przypisanie złych adresów IP należących do innej sieci.
Problemy na warstwie drugiej oraz pierwszej
modelu OSI, mogą zablokować połączenie sieciowe.
Błędna konfiguracja serwera DHCP, mogła
spowodować przypisanie błędnego adresu IP, maski czy adresu bramy D.
Wadliwa konfiguracja połączenia Trunk-owego,
mogła wpłynąć na gubienie pakietów pomiędzy przełącznikiem a ruterem.
Jeżeli pakiet ICPM dotrze do bramy domyślnej, to można założyć, że
Adres IP bramy domyślnej jest osiągalny z poziomu hosta.
Sieć lan przepuszcza ruch unicast pomiędzy hostem a bramą domyślną.
Przełącznik uczy się adresów MAC nadchodzących na jego interfejsy, w ramkach Ethernetowych.
Zaszła wymiana danych pomiędzy hostem a bramą domyślną, mająca na celu obopólną nauką adresów MAC za pomocą protokołu APR(Address Resolution Protocol).
Zasada działania komendy Traceroute
Host wysyła pakiet ICMP z ustawioną wartością
TTL na 1.
Ruter otrzymuje pakiet ICMP, zmniejszając jogo
wartość TTL na 0.
Ruter uznaje, że pakiet przekroczył maksymalną
drogę a jego sieć docelowa jest nieosiągalną.
Ruter odsyła pakiet ICMP z informacją o
nieosiągalności sieci docelowej.
Host wysyła pakiet ICMP, z wartością TTL
zwiększoną o 1.
Proces Troubleshooting-u stanowi proces rozwiązywania problemów sieciowych.
Prosta metoda rozwiązywania problemów
Problem Report – Szczegółowe zdefiniowanie problemu.
ProblemDiagnosis – Określenie prawdopodobnej przyczyny (Postawienie hipotezy)
ProblemResolution – Podjęcie próby naprawy występującego problemu.
Złożona metoda rozwiązywania problemów
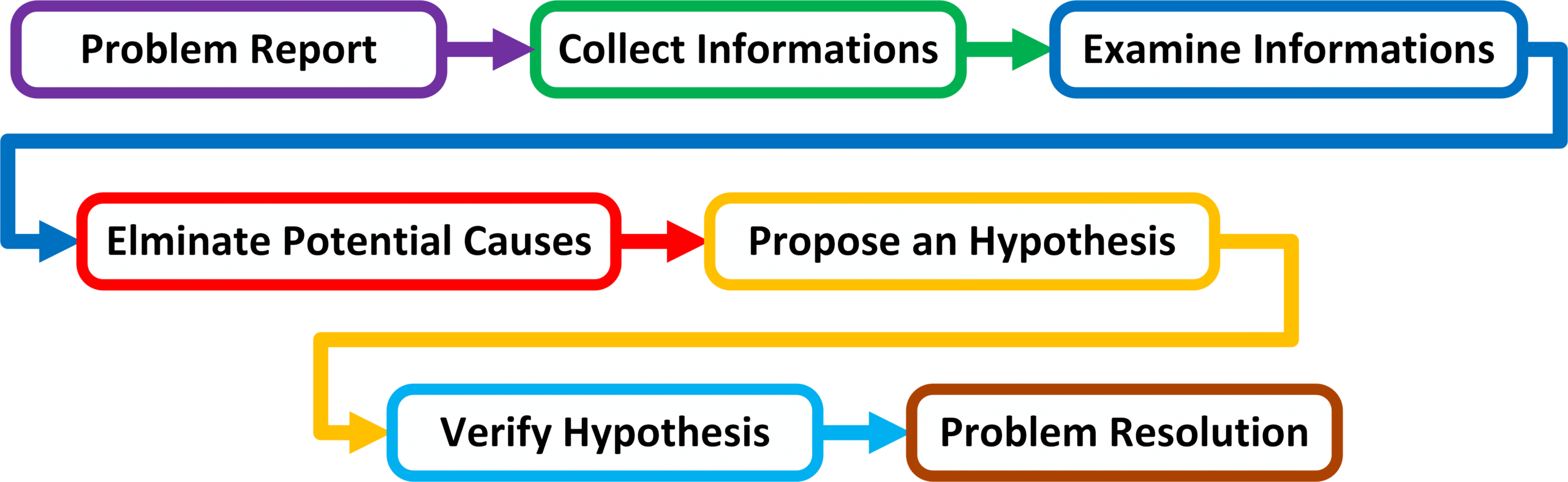
Złożona metoda rozwiązywania problemów rozbija punkt „Problem Diagnosis” przedstawiony w powyższym diagramie na pięć oddzielnych punktów, definiując tym samym siedem kroków w rozwiązywaniu problemów sieciowych.
Złożona metoda rozwiązywania problemów
Problem Report – Szczegółowe zdefiniowanie problemu.
Collect Informations – Zebranie dodatkowych informacji za pomocą dedykowanych narzędzi sieciowych czy rozmów z użytkownikami dotkniętych danym problemem.
Examine Collect Informations – Porównanie między sobą informacji zebranych z rożnych źródeł.
Elminate Potential Causes – Eliminacja prawdopodobnych przyczyn powstania problemu na podstawie zebranych informacji z punktu drugiego oraz z punktu trzeciego.
Propose an Hypothesis – Wysnucie hipotezy co do przyczyny powstania problemu na podstawie zebranych informacji.
Verify Hypothesis – Sprawdzenie wysnutej hipotezy za pomocą dedykowanych narzędzi sieciowych.
Problem Resolution – Podjęcie próby naprawy występującego problemu.
Podejście strukturalne
Strukturalne podejście do rozwiązywania problemów sieciowych, powinno być dostosowywane do panującej sytuacji danego problemu. Struktura ta umożliwia pominięcie niektórych kroków sytuacji w której umożliwi to przyspieszenie samego procesu.
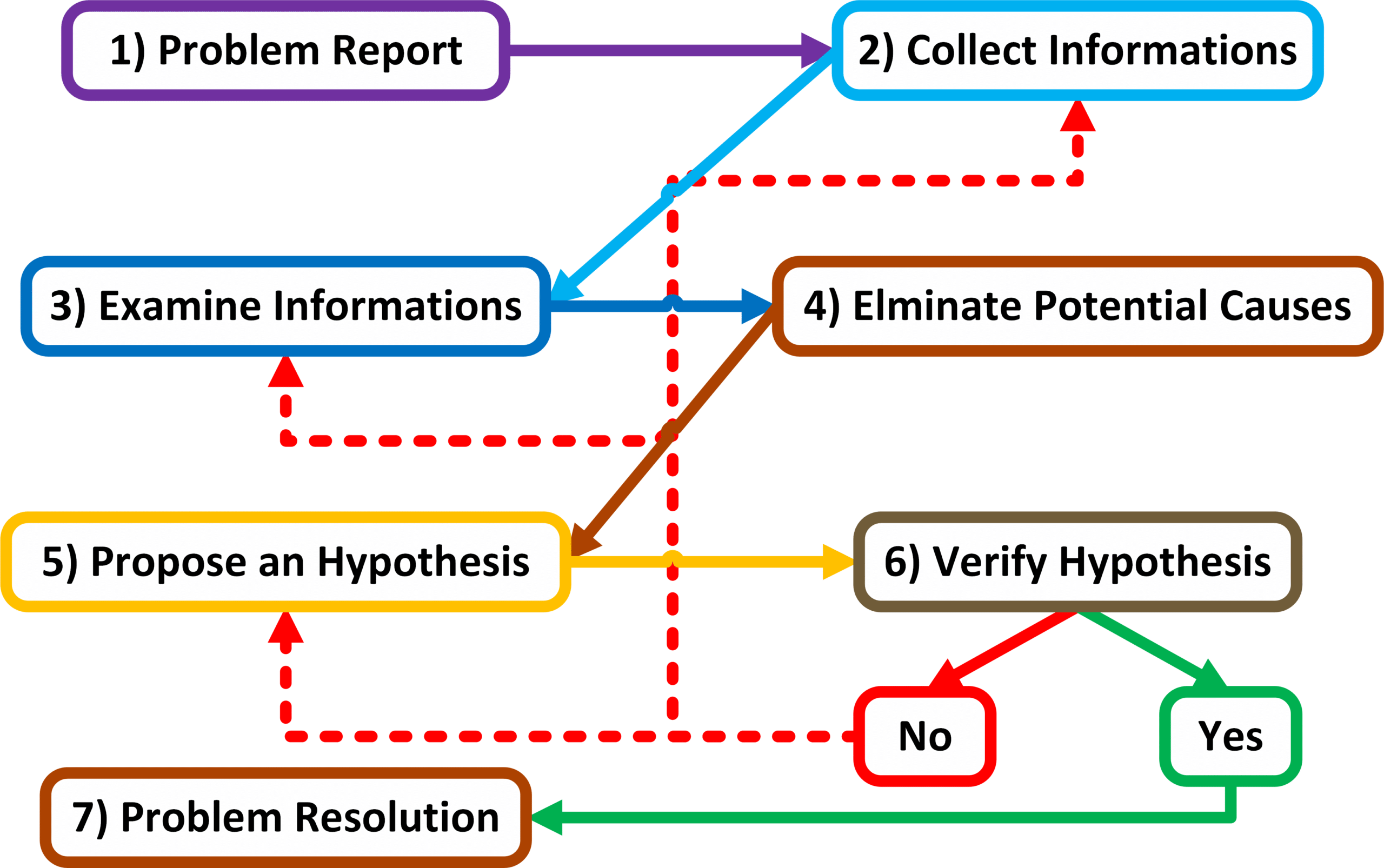
Strukturalny model rozwiązywania problemów sieciowych
Problem
Report
Szczegółowe zdefiniowanie problemu wymaga od administratora zebrania podstawowych danych od użytkownika zgłaszającego problem. W punkcie tym należy określić jakiego rodzaju jest to problem oraz kto powinien się nim zająć.
Przykładowo użytkownik zgłasza problem z brakiem dostępu do Internetu, po sprawdzeniu okazuje się że użytkownikowi wyskakuje „error 404” przy czym komunikacja z wewnętrznym serwerem http działa poprawnie.
Collect
Informations
Zebranie dodatkowych informacji za pomocą dedykowanych narzędzi sieciowych czy rozmów z użytkownikami dotkniętych danym problemem, wymaga od administratora wiedzy na temat zasad działania zasobów co do których wystąpił problem. Wiedza ta umożliwia oszczędzenie czasu, ponieważ administrator skupia się na zebraniu informacji z urządzeń oraz od osób które w sposób bezpośredni bądź pośredni związane z procesem działania danego zasobu.
Przykładowo problem związany z dostępnością serwerem FTP, może wynikać z błędnej konfiguracji lokalnego programu FTP a nie koniecznie dotyczyć komunikacji komputera z serwerem tudzież samego serwera FTP. Wiedząc to administrator wpierw skupi się na sprawdzeniu konfiguracji lokalnego urządzenia, zamiast marnować czas na weryfikacje ustawień sieciowych.
Examine
Informations
Po zebraniu niezbędnych informacji na temat danego problemu, takich jak logging-i, wydruki komend „show” oraz „debug”, pakiety przechwycone przez programy śledzące typu „Sniffer” czy wyniki operacji „ping” jak i „traceroute”. Administrator powinien zidentyfikować wskaźniki wskazujące na przyczynę powstawania problemu jak i dowody wspomagające dalszą weryfikację. Wykonując to zadanie administrator powinien porównać ze sobą dwie wartości: to jak konfiguracja sieci wygląda z tym jak wyglądać powinna.
W tym punkcie procesu rozwiązywania problemów sieciowych istotną rolę gra aktualna dokumentacja sieciowa.
Przykładowo użytkownik może być nie świadomy że komunikacja z serwerem FTP wymaga posiadania dodatkowej aplikacji, zweryfikowanie tego z dokumentacją uwidacznia przyczynę powstania danego problemu.
Elminate
Potential Causes
Eliminacja prawdopodobnych przyczyn powstania problemu na podstawie zebranych informacji.
Propose
an Hypothesis
Po wyborze najbardziej prawdopodobnych przyczyn powstania problemu, na podstawie zabranych informacji, administrator może skupić się na pozostałych teoriach formując na ich podstawie hipotezę.
Verify
Hypothesis
Po określeniu najbardziej prawdopodobnej hipotezy, należy ją zweryfikować a następnie przygotować plan naprawy danego problemu. Może być to rozwiązanie zarówno stałe jak i tymczasowe.
Problem
Resolution
Podjęcie próby naprawy występującego problemu.
Popularne metody Troubleshooting-u
Metody rozwiązywania problemów
The top-down method (7 ->1) – Metoda rozpoczynająca proces troubleshooting-u od warstwy aplikacji (7) a kończąca na warstwie fizycznej (1).
The bottom-up method (1 ->7) – Metoda rozpoczynająca proces troubleshooting-u od warstwy fizycznej (1) a kończąca na warstwie aplikacji (7).
The divide-and-conquer method (1 <- 3 -> 7) – Metoda rozpoczynająca proces troubleshooting-u od warstwy trzeciej (3) a następnie idąca w górę do warstwy aplikacji (7) bądź w dół od warstwy fizycznej (1), w zależności od osiągniętego rezultatu. Jeżeli np. komenda Ping nie osiągnie zamierzonego celu, administrator uzna że błąd dotyczy warstw niższych.
Following the traffic path – Metoda rozpoczynająca proces troubleshooting-u od weryfikacji połączenia pomiędzy hostem zgłaszającym problem a najbliższym urządzeniem sieciowych. W kolejnym kroku weryfikacji podlega następne urządzenie stojące na drodze od hosta do celu danej transmisji.
Comparing configurations – Metoda rozpoczynająca proces troubleshooting-u od porównania konfiguracji bieżącej z ostatnią znaną i wypełni sprawną konfiguracją.
Component swapping – Metoda rozpoczynająca proces troubleshooting-u od wymiany komponentów. Przykładowo wymianie takiej może podlegać kabel Ethernet-owy, pojedynczy moduł rutera bądź całe urządzenie sieciowe.
Konserwacja sieci (Maintenance)
Definicja procesu konserwacji sieci
Proces konserwacji pozwala utrzymać sieć w stanie spełniającym wymogi założeń biznesowych, związanych z funkcjonowaniem i dostępnością sieci. Przykładowe czynności zaliczane do procesu konserwacji są następujące:
Instalacja i konfiguracja urządzeń sieciowych.
Rozwiązywanie problemów (Troubleshooting).
Monitorowanie i zwiększanie wydajności sieci.
Tworzenie dokumentacji sieci jak i zmian w niej dokonywanych.
Sprawdzanie sieci pod kontem zgodności z prawem oraz standardami firmowymi.
Zabezpieczanie sieci przed zewnętrznymi jak i wewnętrznymi zagrożeniami.
Tworzenie kopi zapasowych.
Proaktywne (Proactive) & Reaktywne (Reactive) podejście do konserwacji
sieci
Podejście do procesu konserwacji sieci może być podjęte na dwa sposoby:
Interrupt-driven Tasks – Obejmuje proces rozwiązywania problemów w miarę ich zgłaszania.
Sructured Tasks – Obejmuje proces rozwiązywania problemów w sposób zaplanowany. Dzięki czemu możliwe staje się zapobieganie awariom, zanim staną się one poważnym problemem dla całej infrastruktury. Podejście to odnosi się również do planowanych inwestycji, w wymianę istniejącego jak i zakup nowego sprzętu oraz oprogramowania.
W celu uproszczenia procesu konserwacji sieci, stworzono wiele ustandaryzowanych procedur takich jak:
Poszczególne elementy procesu konserwacji sieci wyglądają następująco:
Fault Management – Za pomocą narzędzi monitorujących jak i zbierających dane na temat stanu infrastruktury sieciowej, nadzoruje czy utylizacja urządzeń oraz przepustowość linków nie przekracza dopuszczalnej normy.
Configuration Management – Wymaga ciągłej aktualizacji zmian zachodzących w infrastrukturze sieciowej związanych z wymianą urządzeń bądź ich oprogramowania. Proces ten odnosi się również do bieżącej aktualizacji narzędzi monitorujących i zbierających dane na temat stanu infrastruktury sieciowej.
Accounting Management– Nadzorowanie zmian zachodzących w infrastrukturze sieciowej.
Performance Management – Monitorowanie przepustowości połączeń lokalnych LAN oraz zewnętrznych WAN, z uwzględnieniem implementacji jak i nadzorowania funkcji kolejkowania QoS.
Security Management – Wdrażanie jak i monitorowanie zapór ogniowych (Firewall), wirtualnych połączeń prywatnych VPN, systemów prewencyjnych IPS, zabezpieczania dostępu za pomocą funkcji AAA czy nadzorowania polis bezpieczeństwa takich lak np. listy ACL.
Metody konserwacji sieci
Rutynowe zadania konserwacyjne
Rutynowe zadania konserwacyjne stanowią nierozłączną część każdej odpowiednio zaplanowanej infrastruktury sieciowej, są to zadania wykonywane regularnie co godzinie, dzień, tydzień, miesiąc czy rok bądź też nieregularne takie jak dodawanie nowych użytkowników. Przykładowe zadania związane z rutynową konserwacją mogą być następujące:
Configuration changes – Dodawanie nowych użytkowników, urządzeń bądź oprogramowania. Dokonywanie zmian związanych z relokacją obecnych zasobów (Użytkowników, urządzeń) wraz związaną z tym rekonfiguracją systemów.
Replacement of older or failed hardware – Wymiana starych bądź uszkodzonych urządzeń.
Scheduled backup – Tworzenie kopi zapasowych konfiguracji, logging-ów zebranych z urządzeń sieciowych.
Monitoring network performance – Monitorowanie jak i zbieranie informacji na temat utylizacji urządzeń oraz przepustowości linków. Co może uprościć proces troubleshooting-u jak i pomóc w planowaniu nowych inwestycji.
Planowanie zadań konserwacyjnych
Kto zatwierdza zmiany dokonywane w infrastrukturze sieciowej.
Jakie zadania powinny być wykonywane jedynie w oknie czasowym przeznaczonym na zadania konserwacyjne.
Jakie procedury obowiązują podczas przeprowadzania zadań konserwacyjnych.
Jakie kryteria określają sukces bądź porażkę przeprowadzonych zadań konserwacyjnych.
W jaki sposób będą dokumentowane zmiany zachodzące w infrastrukturze sieciowej.
Jakie narzędzia pozwolą przywrócić poprzednią działającą konfiguracje w przypadku niepowodzenia w wdrażaniu nowych rozwiązań bądź aktualizacji obecnej infrastruktury sieciowej.
Prowadzenie dokumentacji sieciowej
Dokumentacja infrastruktury sieciowej
Tworzenie jak i utrzymywanie bieżącej dokumentacji infrastruktury sieciowej ułatwia proces troubleshooting-u, ponieważ administrator w łatwy sposób może rozeznać się w konfiguracji sieci porównując stan obecny z założeniami.
Dokumentacja infrastruktury sieciowej może zwierać fizyczną (Physical) i logiczną (Logical) topologię sieci, konfiguracje poszczególnych urządzeń, procedury zmiany bieżącej konfiguracji, kontakt z osobami odpowiedzialnymi za daną część sieci czy wykaz dokonywanych zmian. Podsumowując dokumentacja infrastruktury sieciowej może zwierać:
Topologię logiczną (Logical Topology).
Topologię fizyczną (Physical Topology).
Listę połączeń pomiędzy urządzeniami.
Inwentarz urządzeń sieciowych.
Spis adresacji sieciowej.
Informacje na temat konfiguracji.
Plany założeń infrastruktury sieciowej.
Przywracanie sieci po awarii
Przywrócenie pełnej funkcjonalności sieci po awarii urządzeń sieciowych, może być dokonane za pomocą:
Z duplikowanego wyposażenia (Hardware) znajdującego się w lokalnym magazynie.
Zapasowego oprogramowania przetrzymywanego na lokalnych serwerach.
Kopi zapasowych (Konfiguracji) pobranych z urządzeń sieciowych.
#show
interfaces interfejs pruning– Wyświetla stan
funkcji pruning
dla sieci VLAN na danym interfejsie.
#show
interface interfejs trunk –
Wyświetla konfigurację interfejsu pod kontem połączenia Trunk-owego. Komenda
składa się z trzech pozycji kolejno wyświetlających następujące informacje:
Vlans allowed on trunk – Wyświetla sieci VLAN
dozwolone do ruchu na określonym połączeniu.
Vlans allowed and active in
management domain
– Wyświetla tylko aktywne sieci VLAN dozwolone do ruchu na określonym
połączeniu trunk-owym.
Vlans in spanning tree
Forwarding state and not pruned – Wyświetla nieblokowane przez protokół STP, sieci VLAN dla
określonego połączenia trunk-owego.
#show
interface interfejs switchport –
Wyświetla konfigurację interfejsu pod kontem sieci VLAN (Access, Trunk).
#show
interface status – Wyświetla informacje o statusie (Up) interfejsu
oraz o trybie pracy (speed i duplex).
# show interfaces status
Port Name Status Vlan Duplex Speed Type
Gi0/0 OOB management connected
routed a-full auto
RJ45
Gi0/1 to Switch2 connected trunk
a-full auto RJ45
Gi0/2 to
Switch2 connected trunk
a-full auto RJ45
Gi0/3 to Router1 connected 2 a-full auto
RJ45
Gi1/0 to Switch3 connected trunk
a-full auto RJ45
Gi1/1 to
Switch3 connected trunk
a-full auto RJ45
a- (np. a-full) – Oznacza, że
połączenie zostało negocjowane automatycznie (Autonegotiation).
! Istnieje możliwość, że stan interfejsu (speed,
duplex) będzie określony jako nauczony dynamicznie (a-half, a-100), chodź w
rzeczywistości auto negocjacja zawiodła. Przykładowo, kiedy jeden z
przełączników działa w trybie auto negocjacji natomiast drugi ma statycznie
ustawione wartości (speed, duplex).
!
Po mimo wadliwych ustawień stanu Duplex, przełącznik może wyświetlać status
interfejsu jako up/up, chodź w rzeczywistości połączenie nie będzie działać
poprawnie.
#show
interface interfejs – Wyświetla
szczegółowe informacje o określonym interfejsie sieciowym.
# show interfaces gigabitEthernet 0/1
GigabitEthernet0/1 is up, line
protocol is up (connected)
Hardware is iGbE, address is fa16.3e14.65c8 (bia fa16.3e14.65c8)
Description: to Switch2
MTU 1500 bytes, BW 1000000 Kbit/sec, DLY 10 usec,
reliability 255/255, txload 1/255,
rxload 1/255
Encapsulation ARPA, loopback not set
Keepalive set (10 sec)
Auto Duplex, Auto Speed, link type is auto, media type is unknown
media type
output flow-control is unsupported, input flow-control is unsupported
Full-duplex, Auto-speed, link type is auto, media type is RJ45
input flow-control is off, output flow-control is unsupported
ARP type: ARPA, ARP Timeout 04:00:00
Last input 00:00:28, output 00:00:00, output hang never
Last clearing of “show interface” counters never
Input queue: 0/2000/0/0 (size/max/drops/flushes); Total output drops:
0
Queueing strategy: fifo
Output queue: 0/0 (size/max)
5 minute input rate 0 bits/sec, 0 packets/sec
5 minute output rate 0 bits/sec, 0 packets/sec
9250 packets input, 518775 bytes, 0 no
buffer
Received 9249 broadcasts (9249
multicasts)
0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun,
0 ignored
0 watchdog, 9249 multicast, 0 pause
input
423565 packets output, 27079687 bytes, 0
underruns
0 output errors, 0 collisions, 8
interface resets
0 unknown protocol drops
0 babbles, 0 late collision, 0 deferred
1 lost carrier, 0 no carrier, 0 pause
output
0 output buffer failures, 0 output
buffers swapped out
Runts
– Ilość ramek Ethernet-owych niespełniających minimalnej wielkości
(64 bajty).
Giants
– Ilość ramek Ethernet-owych przekraczających maksymalną wielkość
(1518 bajty).
Input
Errors – Ilość otrzymanych
błędnych ramek Ethernet-owych.
CRC
– Ilość ramek Ethernet-owych,
które nie przeszły testu CRC.
Frame
– Ilość ramek Ethernet-owych,
które zawierają błędną końcówkę lub zły format.
Packet
Output – Ogólna liczba
przetworzonych ramek Ethernet-owych.
Output
Errors – Ogólna liczba przetworzonych błędnych ramek Ethernet-owych.
Late
Collisions – Liczba kolizji, które wystąpiły po otrzymaniu 64 bitów
ramki Ethernet-owej.
Collisions
– Liczba kolizji.
Komendy SHOW MAC
#show
mac address-table – Wyświetla wszystkie adresy MAC zapisane na
urządzeniu.
#show
mac address-table static –Wyświetla statycznie
dodane adresy MAC.
#show
mac address-table address adres-MAC –Wyświetla określony
adres MAC.
#show
mac address-table count [vlan
VLAN-id]–Wyświetla ilość adresów MAC przypisanych
do sieci VLAN.
#show
mac address-table aging-time [vlan
VLAN-id]– Wyświetla czas
przechowywania adresów MAC.
#show
mac address-table interface interfejs – Wyświetla adresy
MAC przypisane do określonego interfejsu.
Komendy SHOW Err-disabled
# show interfaces interfejs status – Wyświetla podstawowe informacje na temat
danego interfejsu sieciowego, w tym status, sieć VLAN, typ interfejsu, tryb
pracy speed oraz duplex.
# show interfaces interfejs status err-disabled – Wyświetla informacje na temat stanu
err-disabled względem interfejsu.
Komendy Show (Warstwa trzecia)
Komendy SHOW (Switching)
# Komendy show
dotyczące xxx:
# show – Wyświetla
# show – Wyświetla
# show – Wyświetla
# Komendy show
dotyczące xxx:
# show – Wyświetla
# show – Wyświetla
# show – Wyświetla
Komendy SHOW (Routing)
# Komendy show
dotyczące xxx:
# show – Wyświetla
# show – Wyświetla
# show – Wyświetla
# show – Wyświetla
# Komendy show
dotyczące xxx:
# show – Wyświetla
# show – Wyświetla
# show – Wyświetla
Komendy Clear
Komendy Clear (Switching)
# Komendy clear
dotyczące xxx:
# clear – Czyści
# clear – Czyści
# clear – Czyści
# clear – Czyści
# Komendy clear
dotyczące xxx:
# clear – Czyści
# clear – Czyści
# clear – Czyści
Komendy Clear (Routing)
# Komendy clear
dotyczące xxx:
# clear – Czyści
# clear – Czyści
# clear – Czyści
# clear – Czyści
# Komendy clear
dotyczące xxx:
# clear – Czyści
# clear – Czyści
# clear – Czyści
Komendy Debug
!
Aktywując komendę Debug, co do której istnieje podejrzenie że wyświetli
ona dużą ilość komunikatów. Należy używać linii VTY, ponieważ połączenie
konsolowe ma pierwszeństwo nad innymi operacjami rutera, co mogło by
doprowadzić do zawieszenia systemu Cisco IOS.