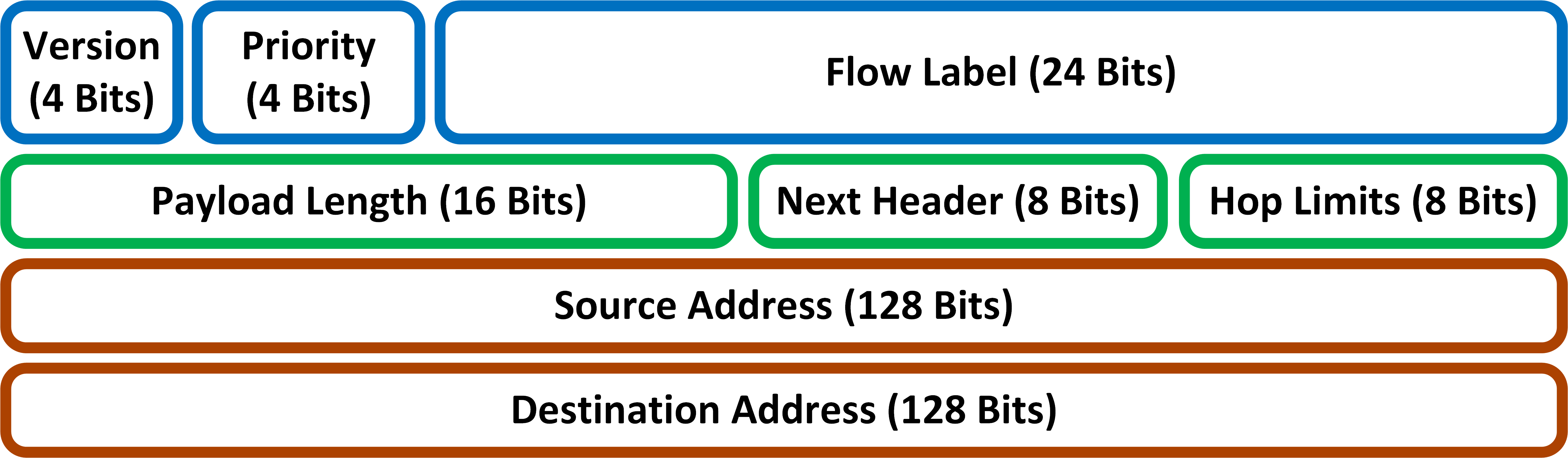
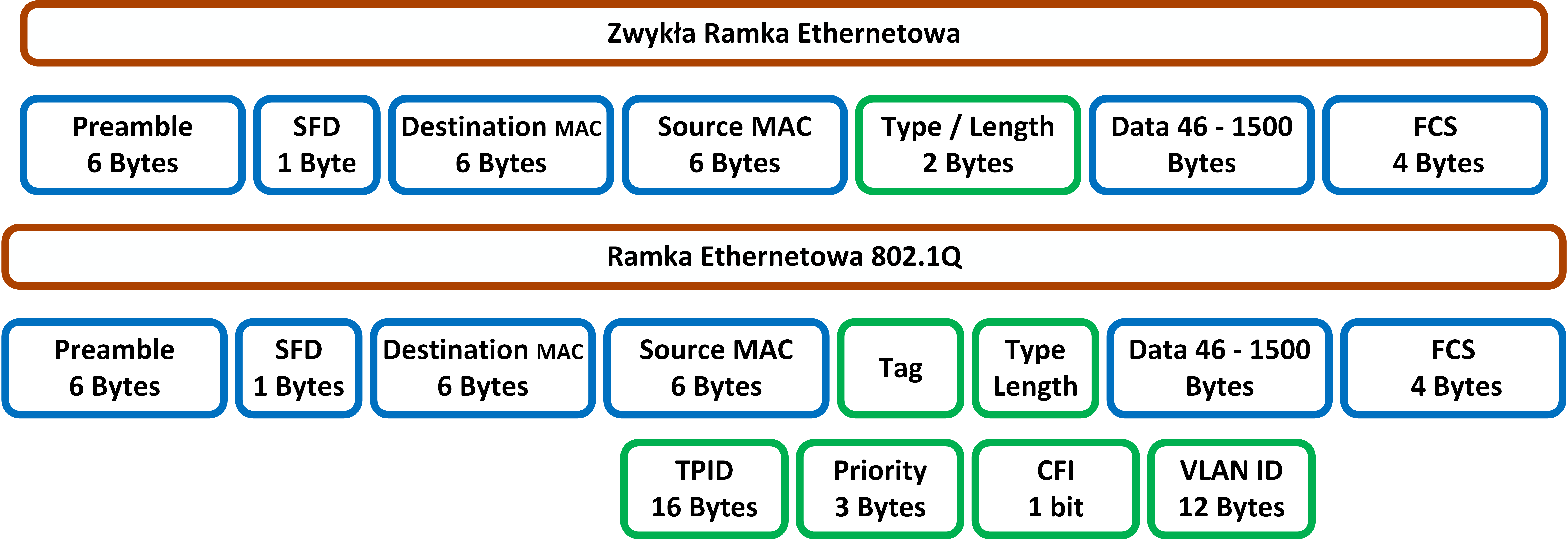
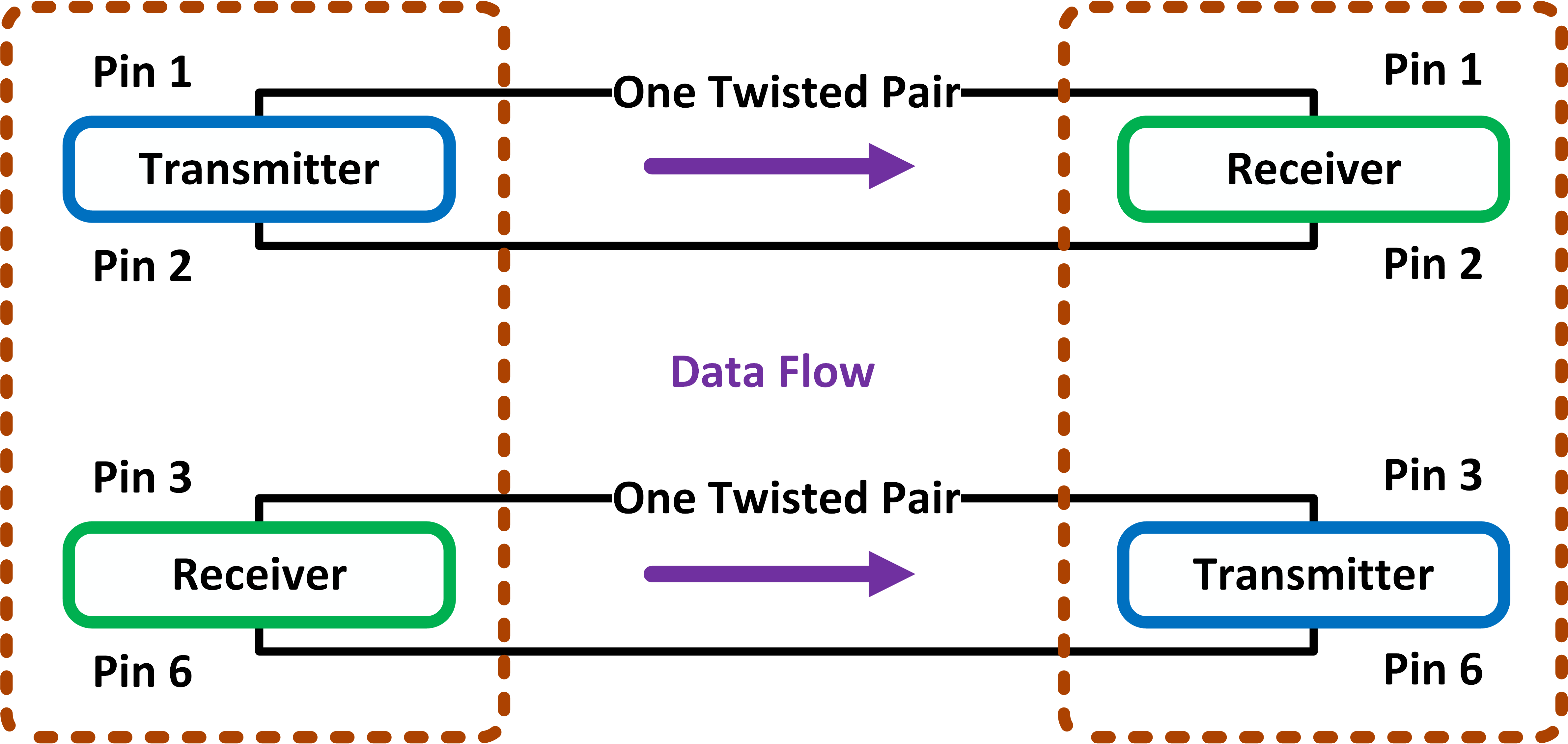
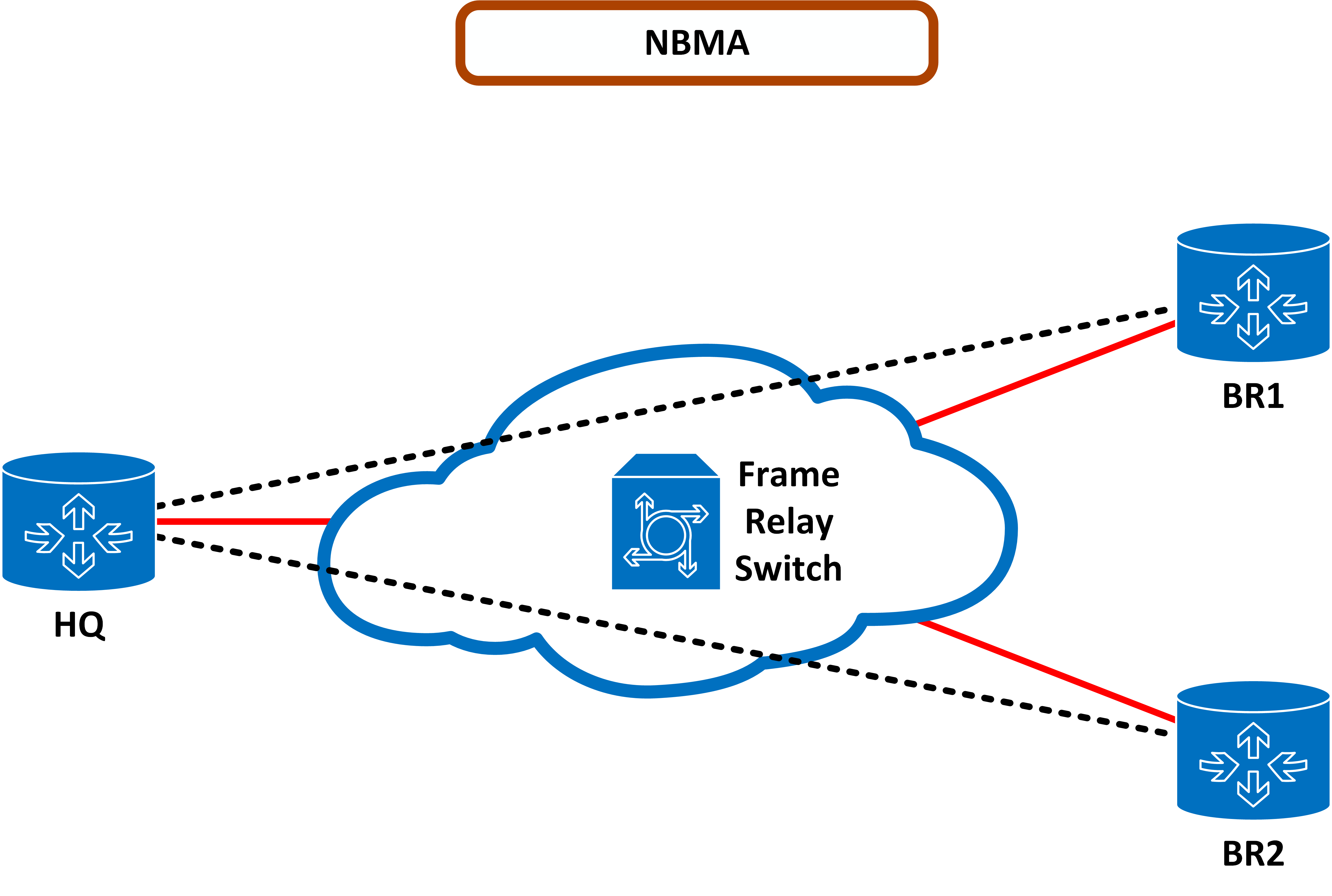
Metody projektowania bezpiecznej sieci
Projektowanie bezpiecznej sieci
- Projektowanie bezpiecznej sieci jest
zadaniem bardzo trudnym, ponieważ różnorodność współczesnych zagrożeń zwiększa
się z każdym dniem. Wymuszając na informatykach posiadanie większej wiedzy
związanej z metodami ochrony informacji oraz infrastruktury sieciowej. W czym
pomagają im pozarządowe organizacje, pracujące nad badaniem i rozwojem nowych
zabezpieczeń. Dzięki wydawanym normą kształtują one standardy znacząco
zwiększające poziom bezpieczeństwa firm, które się do nich stosują. Jedną z
najważniejszych organizacji jest Międzynarodowa Organizacja Normalizacyjna ISO (z
ang. International Organization for Standardization) powstała w 1946 roku w
Londynie. Publikuje ona normy zawierające między innymi standardy projektowania
oraz wdrażania bezpiecznych sieci. - Pojęcie bezpieczeństwa w odniesieniu
do informatyki istniało już od wielu dziesięcioleci jednak dopiero
rozpowszechnienie Internetu uczyniło tą kwestie tak ważną jak jest obecnie. W
przypadku starych niepołączonych ze sobą systemów, istniało bardzo małe
prawdopodobieństwo zainfekowania wirusem komputerowym, ponieważ dane były
przenoszone dyskietkami a każda interakcja ze światem zewnętrznym wymagała
fizycznego kontaktu. Jednak współczesne sieci LAN i WAN pozwalają hackerom na
łatwe odnajdywanie i zarażanie nowych ofiar, w czym często pomagają sami
użytkownicy, zaniedbujący poziom bezpieczeństwa swoich urządzeń, w
szczególności, jeśli należą one do firmy, w której pracują. Dlatego
administrator projektujący sieć musi skrupulatnie przeanalizować każdy element
swojego projektu, nieustanie szukając nowych zagrożeń i luk w zabezpieczeniach.
Etap projektowania testowania i sprawdzania stanu sieci jest cykliczny i
powinien być powtarzany przez cały okres istnienia sieci. Ponieważ brak
skrupulatnego sprawdzania może doprowadzić do włamania się osób niepowołanych,
a tym samym uszkodzenia sieci lub wycieku cennych danych. Dla ułatwienia pracy
proces projektowania można podzielić na segmenty, z których każdy zajmuje się
innym aspektem ułatwiając przygotowanie finalnej konfiguracji oraz
udostępniającym administratorom odpowiednie środki do późniejszego dbania o jej
stan. Mierzenie poziomu bezpieczeństwa, przeprowadzenie analizy ryzyka czy
przygotowanie polityki bezpieczeństwa jest częścią procesu zwanego zarządzaniem
ryzykiem.
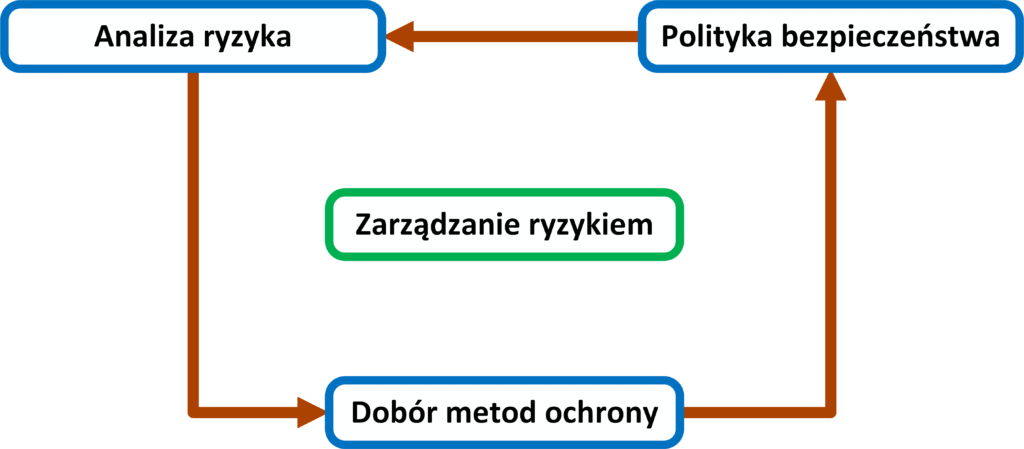
Zarządzanie ryzykiem
- Proces zarządzania ryzykiem składa się z etapów
zajmujących się wykrywaniem, monitorowaniem i analizowaniem zagrożeń oraz
szukaniem metod im przeciwdziałających. Jest to proces powtarzalny, dlatego po
pierwszym wdrożeniu należy sukcesywnie sprawdzać jego efektywność,
systematycznie uaktualniając informacje o obecnym stanie infrastruktury
firmowej. Przede wszystkim należy pamiętać o prostej zasadzie mówiącej, że dla
informatyka stanie w miejscu jest równoznaczne z cofaniem się, dlatego tak
ważne jest okresowe badanie wszystkich elementów zabezpieczeń sieciowych oraz
systematyczne doszkalanie pracowników pod kontem nowych rozwiązań technicznych
dotyczących bezpieczeństwa. - Zarządzanie składa się z etapów, z których
najważniejszymi są: analiza ryzyka, dobór metody ochrony czy przygotowanie
polityki bezpieczeństwa, jako końcowego dokumentu zawierającego wszystkie
procedury firmy, związane z ochroną sieci przed atakami zewnętrznymi jak i
wewnętrznymi oraz metodami im przeciwdziałającymi. Analiza zagrożeń jest etapem
tworzenia spisu wszystkich urządzeń i usług sieciowych wraz z przypisanymi do
nich zagrożeniami, jakie mogą wpłynąć na ich prawidłową prace. Odpowiada na
pytania co, gdzie, po co oraz dlaczego ma chronić. Dzięki uzyskanym informacją
jesteśmy w stanie zdecydować jakie kroki należy podjąć w celu eliminacji
występujących zagrożeń. Następnie w procesie dobierania metody ochrony, zostaje
wyłoniony jak najbardziej efektywny a jednocześnie oszczędny sposób
przeciwdziałania zagrożeniom. Przykładowo jednym z rozwiązań może być zakup
oprogramowania antywirusowego, jeśli zagrożeniem jest połączenie z Internetem.
W innym przypadku ochroną przed uszkodzeniem fizycznym, może być zastosowanie
nadmiarowych połączeń lub dodatkowych urządzeń, dzięki czemu uszkodzenie jednego
z nich nie spowoduje przerwy w łączności z siecią. Ostatnim elementem procesu
jest końcowe spisanie polityki bezpieczeństwa jako zbioru zasad, reguł oraz
wytycznych obowiązujących w firmie, zarówno podczas planowania i wdrażania
infrastruktury sieciowej jak i dalszego jej funkcjonowania. Po zakończeniu
pracy oczywiści nie można zapomnieć o systematycznej obserwacji zmieniającego
się środowiska wewnętrznego oraz zewnętrznego. Bowiem administrator nigdy nie
może uznać swojej sieci za stuprocentowo bezpieczną, zapominając tym samym o
systematycznym sprawdzaniu poziomu jej zabezpieczeń.
Analiza ryzyka
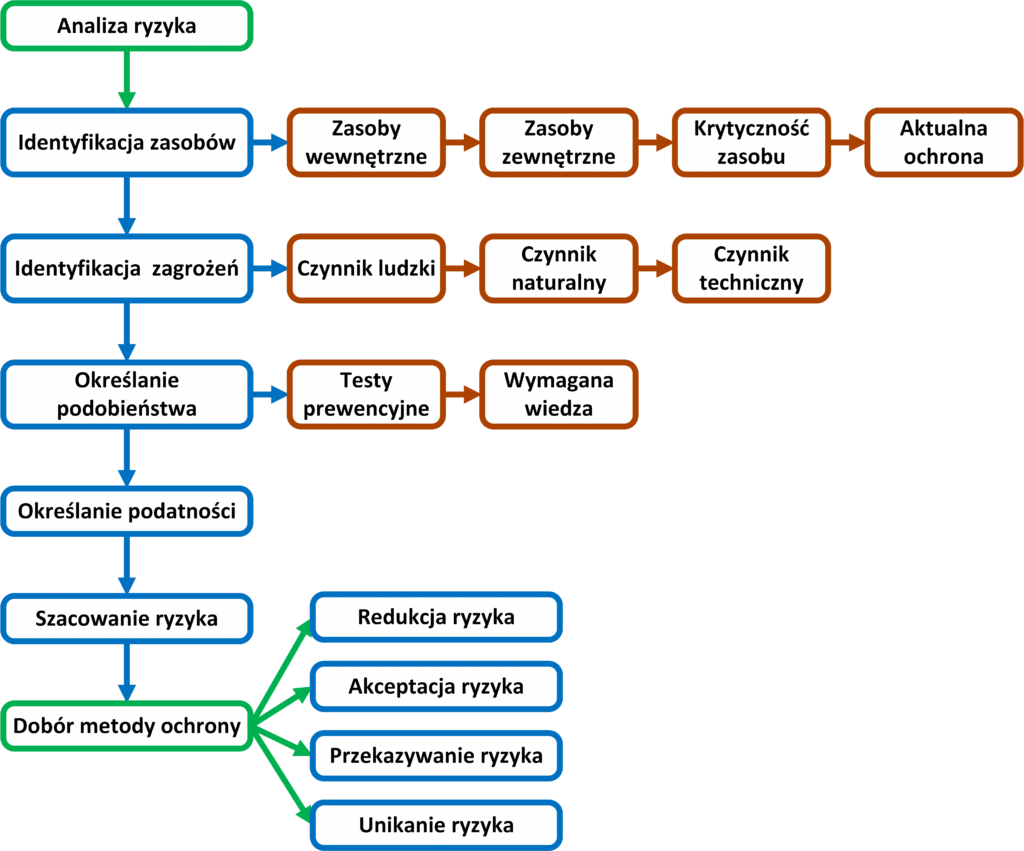
- Analiza ryzyka jest etapem uświadamiania sobie, jakiego rodzaju zagrożenia i w jakim stopniu, mogą wpłynąć na prawidłowe funkcjonowanie sieci. Do pełnego zrozumienia tej koncepcji, należy zapoznać się z znaczeniem podstawowych pojęć funkcjonujących w normie ISO/IEC 27001:2005. Pierwsze pojęcie aktywów dotyczy wszystkich elementów znajdujących się firmie, posiadających wartość materialną lub strategiczną. Drugie zasobów jako miejsca przeznaczonego do przechowywania aktywów, przykładowo różne systemy informatyczne zainstalowane na serwerze będą aktywami natomiast sam serwer będzie zasobem. Ostatnie pojęcie dotyczy bezpieczeństwa informacji, składającego się z trzech cech: poufności, dzięki czemu informacja znana jest jedynie nadawcy i odbiorcy, integralności sprawdzającej czy wiadomość nie była modyfikowana przez osobę do tego nieuprawnioną oraz dostępności dbającej o kontrolowany dostęp do informacji. Proces analizowania ryzyka składa się z pięciu etapów, z których każdy jest konieczny do osiągnięcia skutecznej ochrony.
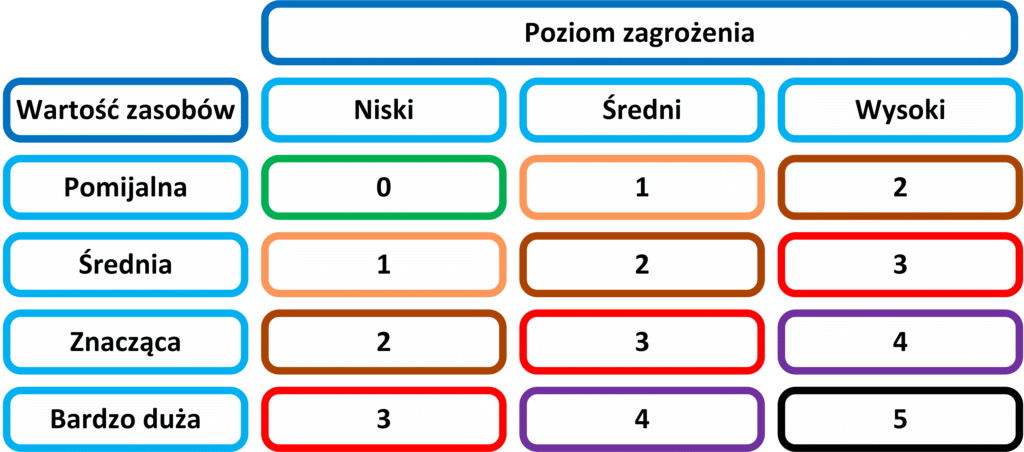
- Pierwszy etap identyfikacji, polega na przeprowadzeniu inwentaryzacji wszystkich zasobów sieciowych firmy oraz ocenie ich znaczenia. Ponieważ bez znajomości urządzeń, jakie posiadamy nie jesteśmy w stanie o nie zadbać. Podczas określania wartości poszczególnych zasobów, należy uwzględnić ich wartość strategiczną, jak i rozważyć wpływ, jaki będzie miała ich utrata na funkcjonowanie całej firmy. Im większy wpływ tym większa wartość zasobu, oceniana przeważnie przez pryzmat wartości materialnej (finansowej). Oczywiście istnieją zasoby takie jak wizerunek czy opinia o firmie, których nie da się prosto przeliczyć na pieniądze, dlatego wartość poszczególnych zasobów można oceniać porównując je między sobą zgodnie z następującymi wartościami:
- Bardzo duża – Utrata lub uszkodzenie zasobu uniemożliwia funkcjonowanie firmy.
- Znacząca – Utrata lub uszkodzenie zasobu ma wpływ na funkcjonowanie firmy.
- Średnia – Utrata lub uszkodzenie zasobu powoduje utrudnienia w normalnym funkcjonowaniu firmy.
- Pomijalna – Utrata lub uszkodzenie zasobu nie ma wpływ na funkcjonowanie firmy.
- Opisując poszczególne zasoby, należy określić, czy należą one do lokalnej infrastruktury, nad którą sprawujemy kontrole, mając dostęp do pełnej konfiguracji, czy jest to element sieci utrzymywany dzięki współpracy z innymi firmami, na zasadzie outsourcingu jak zewnętrze centra danych lub jako ogólnodostępne serwery poczty czy DNS. Inną ważną informacją mogą być dane o już istniejących zabezpieczeniach, jeśli przeprowadzamy proces analizy w funkcjonującej firmie albo wykonujemy go ponownie po przeprowadzeniu dużych zmian w infrastrukturze.
- Etap drugi identyfikuje jakiego rodzaju niebezpieczeństwa mogą zagrozić poszczególnym zasobom naszej firmy, dzięki czemu w następnym punkcie będziemy mogli określić poziom zagrożenia dla danego zasobu. Należy wziąć pod uwagę możliwość wystąpienia nadzwyczajnych zagrożeń naturalnych (powodzi, trzęsienia ziemi), czynnika ludzkiego w postaci pracowników firmy lub osób zewnętrznych czy uszkodzeń fizycznych wynikających z długotrwałej eksploracji sprzętu sieciowego. Należy również określić przyczyny powstawania powyższych sytuacji (np. zagrożenia spowodowane przez ludzi mogą wynikać z ataku hackerskiego) jak i szkód, jakie mogą wyrządzić (np. sparaliżowanie usług serwera). Inną ważną informacją jaka powinna się znaleźć w tabeli identyfikującej zagrożenia, jest wpływ na utratę poufności, integralności czy dostępności danych. Przykładowo zgubienie przez administratora pamięci USB może wpłynąć na poufność przechowywanych na niej informacji. Istnieję również przypadki, w których zwiększony poziom dostępności jest osiągany kosztem poufności, na przykład ilość zasobów, na których przechowujemy aktywa firmowe, ma znaczący wpływ na poziom ich bezpieczeństwa. Czym większa liczba oddalonych od siebie lokalizacji przetwarzających dane tym większe zagrożenie utraty poufności, wiążącej się z ryzykiem ujawnienia wrażliwych informacji. Z drugiej strony zwiększenie ilości miejsc przechowujących dane, wpływa na podwyższony poziom ich dostępności. W takiej sytuacji należy podjąć decyzje o tym co jest ważniejsze z punktu widzenia firmy, a tym samym czy warto podjąć ryzyko wynikające z możliwych do wystąpienia zagrożeń. Niezależnie od wielkości sieci, którą opisujemy zawsze można skorzystać z dodatkowej pomocy w postaci przykładowych list zawierających najczęściej występujące zagrożenia przyporządkowane do konkretnych zasobów, dzięki czemu nasza analiza wzbogaci się o opcje które sami mogliśmy pominąć bądź niemieliśmy o nich wiedzy. Przede wszystkim należy pamiętać, aby wszystkie przypisane do zasobów zagrożenia były jak najbardziej realnymi scenariuszami, dzięki czemu uzyskamy aktualne i miarodajne wyniki.
- Po identyfikacji zasobów (etap pierwszy) i przyporządkowaniu do nich możliwych zagrożeń (etap drugi) należy określić jak realne są to niebezpieczeństwa oraz jakie jest prawdopodobieństwo ich wystąpienia. Przykładowo awaria zasilania jest bardziej prawdopodobna niż sunnami czy trzęsienie ziemi w środkowej Polsce. Dodatkową praktyką stosowaną przez wiele firm jest przeprowadzanie testów prewencyjnych, podczas których następuje symulacja ataku na infrastrukturę IT. Dzięki czemu staje się możliwe wykrycie luk w zabezpieczeniach sieci. Tak samo jak w przypadku identyfikacji zasobów, tak i szacowaniu ryzyka możemy określić prawdopodobieństwo wystąpienia zagrożenia przy pomocy określonych wartości wykorzystywanych w metodzie jakościowej lub zastosować wyliczenia oparte na konkretnych liczbach (związanych z wartością finansową zasobu) przy zastosowaniu metody ilościowej.
- Poziom szacowania zagrożenia metoda jakościową:
- Wysoki – Występuje często (np. raz w miesiącu), regularnie.
- Średni – Występuje rzadko (np. raz w roku), nieregularnie.
- Niski – Nie wystąpiło w przeciągu roku.
- Po określeniu, co chcemy chronić, dlaczego chcemy to robić i przed czym to robimy, należy ustalić, jakie są słabe punkty zasobów, przez co stają się podatne na ataki czy inne zagrożenia. Przykładowo w sytuacji, gdy firma łączy się pomiędzy swoimi oddziałami za pomocą sieci publicznej, możemy stwierdzić, że przesyłane przez nią wrażliwe informacje (aktywa) mogą zostać odczytane (zagrożone) przez osobę niepowołaną, dlatego należy dodatkowo zabezpieczyć urządzenia (zasoby) uczestniczące w komunikacji. Pamiętając, że na tym etapie określamy jedynie właściwości zasobów, które mogą zostać wykorzystane podczas ataku a nie metody im zapobiegające.
- Ostatni etap polega na oszacowaniu istniejącego ryzyka dla poszczególnych aktywów, zasobów względem ich wartości strategicznej, na podstawie przeprowadzonej analizy, przed zastosowaniem środków zabezpieczających. W tym celu tworzymy tabelę opartą o dane zabrane w poprzednich punktach, uzyskując tym samym liczbową wartość istniejącego ryzyka, wystąpienia zagrożenia dla rozpatrywanych aktywów lub zasobów. Dodatkową praktyką ułatwiającą późniejsze wprowadzanych zmian w poziomie zabezpieczeń firmy, jest określenie ryzyka akceptowalnego. Stanowi ono poziom określający w jakich przypadkach należy niezwłocznie zająć się istniejącym zagrożeniem a w jakim interwencja nie jest pilna i może być odroczona w czasie. Przykładowo w poniższej tabeli granicą ryzyka akceptowalnego może być poziom pomiędzy numerem drugim a trzecim.
Dobór metod ochrony
- Po przeprowadzeniu procesu analizy ryzyka, należy wdrożyć metody minimalizujące możliwość wystąpienia określonych zagrożeń. Szczególnie w sytuacji, gdy przekraczają one ustaloną wartość ryzyka akceptowalnego. Istnieją cztery wzajemnie wykluczające się podejścia, do sposobu podejmowania decyzji o ich redukcji. Każde należy rozpatrzyć indywidualne wzglądem poszczególnych aktywów lub zasobów:
- Redukcja ryzyka – Polega na wdrożeniu środków, mających zredukować ryzyko wystąpienia zagrożenia. Przykładowo po ustaleniu, że serwer może być zagrożony atakiem hackerskim i jest to bardzo prawdopodobne, a jednocześnie posiadanie przez firmę serwera konieczne, należy wprowadzić metody zabezpieczające, niezależnie od ich kosztów. Może być to zakup np. zapory ogniowej zapewniającej ochronę przed atakami czy urządzenia IPS przeznaczonego do analizowania ruchu sieciowego.
- Akceptacja ryzyka – W przypadku, gdy, cena redukcji zagrożenia jest zbyt wysoka a niebezpieczeństwo wystąpienia niskie, można zaakceptować możliwość jego zajścia bez podejmowania kroków mających wyeliminować możliwość jego wystąpienia.
- Przekazywania ryzyka – Może przybrać formę ubezpieczenia czy „outsourcing-u”[1], przerzucając ryzyko wystąpienia zagrożenia na inną firmę, przeważnie dysponującą kadrą bardziej wykwalifikowanych i doświadczonych informatyków.
- Uniknięcie ryzyka – W przypadku istnienia zbyt dużego zagrożenia, względem niskich korzyści wynikających z użytkowania danego aktywu, firma może podjąć decyzje o zaprzestaniu dalszego używania danego elementu infrastruktury, w celu całkowitego wykluczenia możliwość wystąpienia zagrożenia.
Polityka bezpieczeństwa
- Po wybraniu metod przeciwdziałających
zagrożeniom, poprzedzonych analizą ryzyka, następuje etap spisania polityki
bezpieczeństwa. Zbioru zasad, reguł i wytycznych, którymi administrator kieruje
się przy tworzeniu i rozbudowie sieci. Jego treść będzie pomocna zarówno przy
konfiguracji i wdrażaniu całej infrastruktury, jak i przez cały czas
funkcjonowania firmy. Dlatego musi zawierać informacje o zasadach przetwarzania i
dostępu do danych, codziennych zachowań pracowników pod względem bezpieczeństwa
oraz procesu przyznawania
dostępu do zasobów i ochrony przed wyciekiem informacji. Istnieje powiedzenie
„Człowiek najsłabszym elementem bezpieczeństwa IT”, dlatego należy pamiętać, że
zbyt rozbudowane środki ostrożności, szczególnie opisane technicznym językiem,
mogą spowolnić pracę lub wręcz zniechęcić pracowników do ich stosowania.
Konieczne jest więc, ich uświadamianie poprzez kursy instruktażowe mające na
celu wyjaśnienie zasad oraz przyczyn istnienia takiej polityki, dobrym
rozwiązaniem są testy bezpieczeństwa sprawdzające reakcje pracowników na
nietypowe prośby działu administracji np. z zapytaniem o podanie hasła i loginu
w celach weryfikacji danych, czego oczywiście nigdy nie powinni robić.
Pozostałe tematy związane z bezpieczeństwem
Podstawy sieci komputerowych
Warstwy modelu OSI
- Model TCP/IP
- Warstwa pierwsza modelu OSI
- Warstwa druga modelu OSI
- Warstwa trzecia modelu OSI
- Warstwa czwarta modelu OSI
Bezpieczeństwo sieci
Troubleshooting
- Troubleshooting & Maintenance
- Narzędzia Troubleshooting-u
- Troubleshooting wydajności urządzeń sieciowych
[1] Outsourcing – Stanowi część struktury organizacyjnej wydzielonej z firmy i przekazanej do wykonania oraz nadzorowania innym podmiotom.