Zapisuje zrzut pamięci urządzenia sieciowego (Core dump) wraz z czasem wystąpienia błędu krytycznego. W następstwie którego urządzenie te zostanie zresetowane. Na wskazany w komendzie adres IP zostanie wysłany zapisany zrzut pamięci wraz z datą (Za pomocą protokołu TFTP).
Błędy krytyczne (zrzut FTP)
(config)#ip ftp username login
Definiuje login użytkownika, wykorzystywany przez protokół FTP.
(config)#ip ftp password hasło
Definiuje hasło użytkownika, wykorzystywane przez protokół FTP.
(config)#exception protocol ftp
Wykonuje zrzut pamięci urządzenia sieciowego (Core dump), przy wykorzystaniu protokołu FTP.
IP SLA – Monitoruję osiągalność wyznaczonego adresu IP.
SNMP – Umożliwia zaawansowane śledzenie aktywności wielu urządzeń.
Cisco Support– Prowadzi wsparci za pomocą serwisów CMS bądź TAC.
Komenda Ping i Traceroute
Możliwe przyczyny braku odpowiedzi na pakiet ICPM
Lista ACL blikująca ruch sieciowy po adresach IP
czy portach TCP, UDP (List ACL nie może filtrować ruchu wychodzącego,
zainicjonowanego przez urządzenie, na którym sama powstała jak i funkcjonuje).
Funkcja „PortSecurity” włączona na przełączniku
w celu filtrowania np. adresów MAC, może wyłączyć interfejs blokując tym samym
cały ruch na niego przychodzący bądź z niego wychodzący.
Złe ustawienia trasy domyślnej w tablicy
routingu, mogą kierować nadpływający ruch sieciowy w złym kierunku.
Błędna adresacja urządzeń, może spowodować
przypisanie złych adresów IP należących do innej sieci.
Problemy na warstwie drugiej oraz pierwszej
modelu OSI, mogą zablokować połączenie sieciowe.
Błędna konfiguracja serwera DHCP, mogła
spowodować przypisanie błędnego adresu IP, maski czy adresu bramy D.
Wadliwa konfiguracja połączenia Trunk-owego,
mogła wpłynąć na gubienie pakietów pomiędzy przełącznikiem a ruterem.
Jeżeli pakiet ICPM dotrze do bramy domyślnej, to można założyć, że
Adres IP bramy domyślnej jest osiągalny z poziomu hosta.
Sieć lan przepuszcza ruch unicast pomiędzy hostem a bramą domyślną.
Przełącznik uczy się adresów MAC nadchodzących na jego interfejsy, w ramkach Ethernetowych.
Zaszła wymiana danych pomiędzy hostem a bramą domyślną, mająca na celu obopólną nauką adresów MAC za pomocą protokołu APR(Address Resolution Protocol).
Zasada działania komendy Traceroute
Host wysyła pakiet ICMP z ustawioną wartością
TTL na 1.
Ruter otrzymuje pakiet ICMP, zmniejszając jogo
wartość TTL na 0.
Ruter uznaje, że pakiet przekroczył maksymalną
drogę a jego sieć docelowa jest nieosiągalną.
Ruter odsyła pakiet ICMP z informacją o
nieosiągalności sieci docelowej.
Host wysyła pakiet ICMP, z wartością TTL
zwiększoną o 1.
Proces Troubleshooting-u stanowi proces rozwiązywania problemów sieciowych.
Prosta metoda rozwiązywania problemów
Problem Report – Szczegółowe zdefiniowanie problemu.
ProblemDiagnosis – Określenie prawdopodobnej przyczyny (Postawienie hipotezy)
ProblemResolution – Podjęcie próby naprawy występującego problemu.
Złożona metoda rozwiązywania problemów
Złożona metoda rozwiązywania problemów rozbija punkt „Problem Diagnosis” przedstawiony w powyższym diagramie na pięć oddzielnych punktów, definiując tym samym siedem kroków w rozwiązywaniu problemów sieciowych.
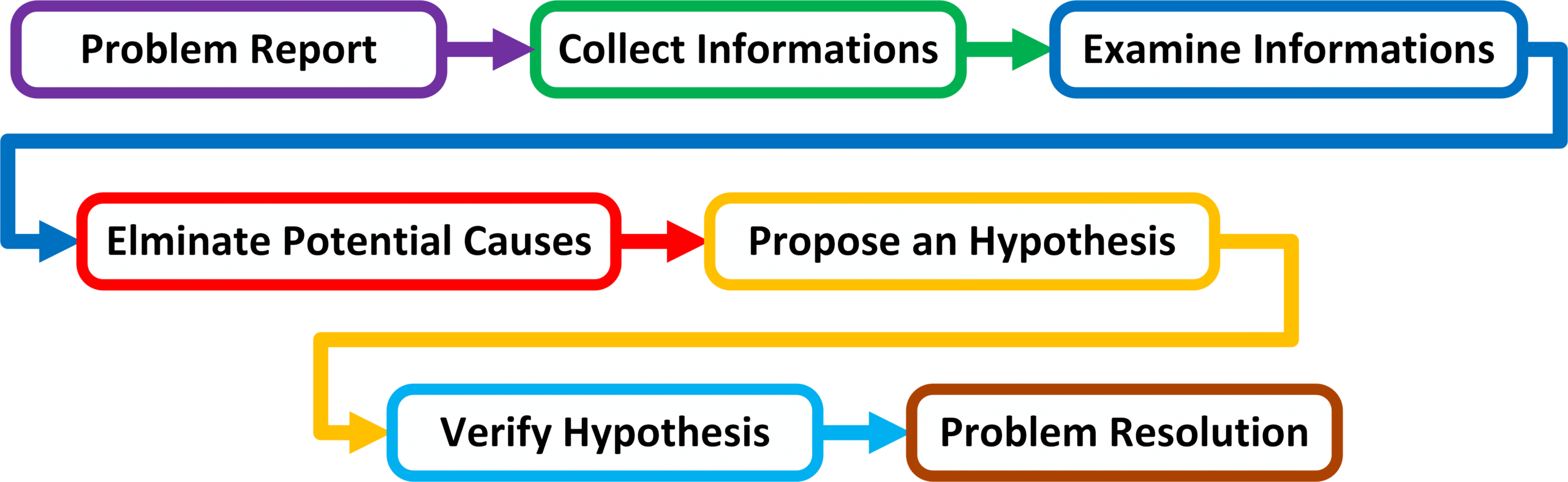
Złożona metoda rozwiązywania problemów
Problem Report – Szczegółowe zdefiniowanie problemu.
Collect Informations – Zebranie dodatkowych informacji za pomocą dedykowanych narzędzi sieciowych czy rozmów z użytkownikami dotkniętych danym problemem.
Examine Collect Informations – Porównanie między sobą informacji zebranych z rożnych źródeł.
Elminate Potential Causes – Eliminacja prawdopodobnych przyczyn powstania problemu na podstawie zebranych informacji z punktu drugiego oraz z punktu trzeciego.
Propose an Hypothesis – Wysnucie hipotezy co do przyczyny powstania problemu na podstawie zebranych informacji.
Verify Hypothesis – Sprawdzenie wysnutej hipotezy za pomocą dedykowanych narzędzi sieciowych.
Problem Resolution – Podjęcie próby naprawy występującego problemu.
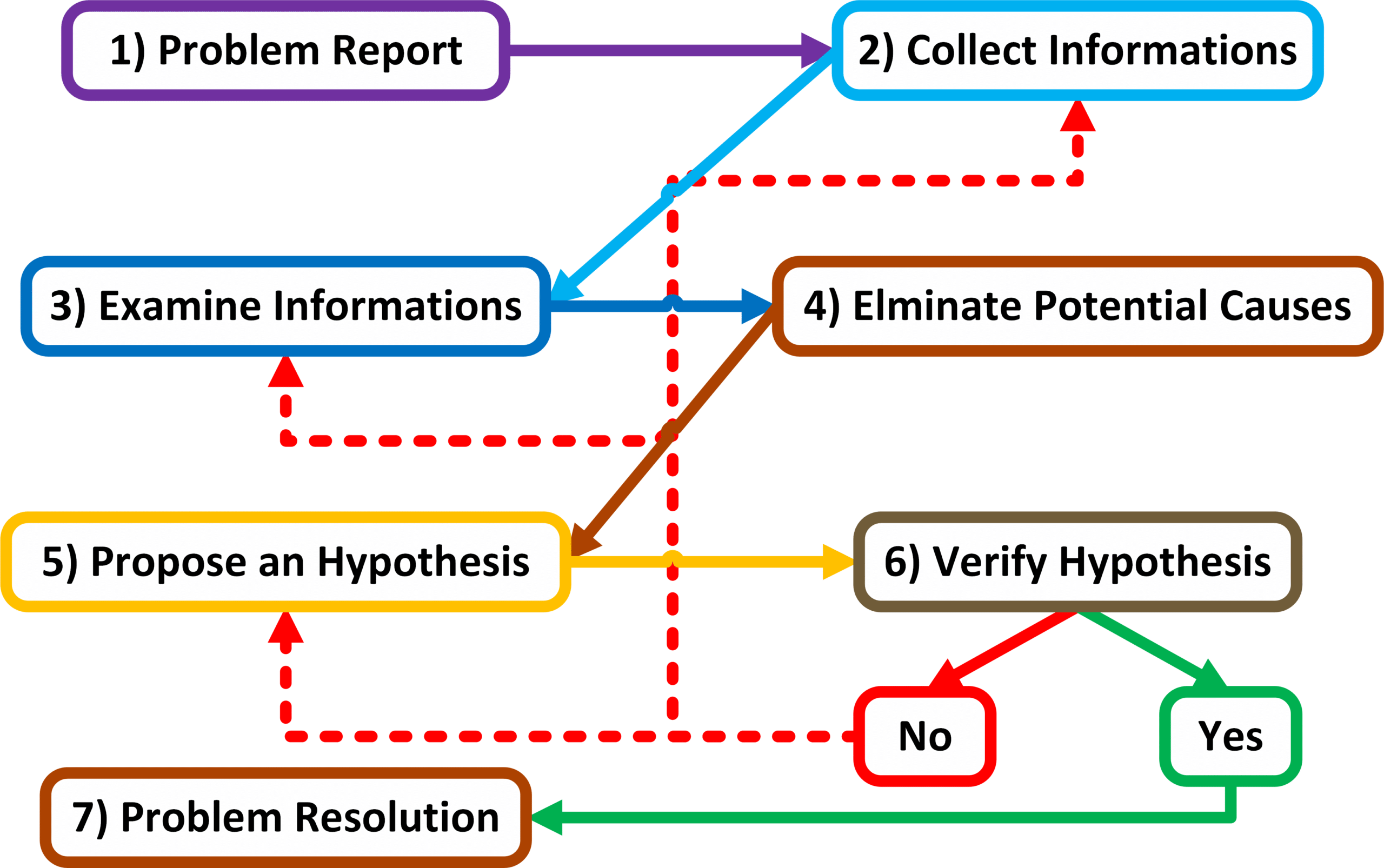
Podejście strukturalne
Strukturalne podejście do rozwiązywania problemów sieciowych, powinno być dostosowywane do panującej sytuacji danego problemu. Struktura ta umożliwia pominięcie niektórych kroków sytuacji w której umożliwi to przyspieszenie samego procesu.
Strukturalny model rozwiązywania problemów sieciowych
Problem
Report
Szczegółowe zdefiniowanie problemu wymaga od administratora zebrania podstawowych danych od użytkownika zgłaszającego problem. W punkcie tym należy określić jakiego rodzaju jest to problem oraz kto powinien się nim zająć.
Przykładowo użytkownik zgłasza problem z brakiem dostępu do Internetu, po sprawdzeniu okazuje się że użytkownikowi wyskakuje „error 404” przy czym komunikacja z wewnętrznym serwerem http działa poprawnie.
Collect
Informations
Zebranie dodatkowych informacji za pomocą dedykowanych narzędzi sieciowych czy rozmów z użytkownikami dotkniętych danym problemem, wymaga od administratora wiedzy na temat zasad działania zasobów co do których wystąpił problem. Wiedza ta umożliwia oszczędzenie czasu, ponieważ administrator skupia się na zebraniu informacji z urządzeń oraz od osób które w sposób bezpośredni bądź pośredni związane z procesem działania danego zasobu.
Przykładowo problem związany z dostępnością serwerem FTP, może wynikać z błędnej konfiguracji lokalnego programu FTP a nie koniecznie dotyczyć komunikacji komputera z serwerem tudzież samego serwera FTP. Wiedząc to administrator wpierw skupi się na sprawdzeniu konfiguracji lokalnego urządzenia, zamiast marnować czas na weryfikacje ustawień sieciowych.
Examine
Informations
Po zebraniu niezbędnych informacji na temat danego problemu, takich jak logging-i, wydruki komend „show” oraz „debug”, pakiety przechwycone przez programy śledzące typu „Sniffer” czy wyniki operacji „ping” jak i „traceroute”. Administrator powinien zidentyfikować wskaźniki wskazujące na przyczynę powstawania problemu jak i dowody wspomagające dalszą weryfikację. Wykonując to zadanie administrator powinien porównać ze sobą dwie wartości: to jak konfiguracja sieci wygląda z tym jak wyglądać powinna.
W tym punkcie procesu rozwiązywania problemów sieciowych istotną rolę gra aktualna dokumentacja sieciowa.
Przykładowo użytkownik może być nie świadomy że komunikacja z serwerem FTP wymaga posiadania dodatkowej aplikacji, zweryfikowanie tego z dokumentacją uwidacznia przyczynę powstania danego problemu.
Elminate
Potential Causes
Eliminacja prawdopodobnych przyczyn powstania problemu na podstawie zebranych informacji.
Propose
an Hypothesis
Po wyborze najbardziej prawdopodobnych przyczyn powstania problemu, na podstawie zabranych informacji, administrator może skupić się na pozostałych teoriach formując na ich podstawie hipotezę.
Verify
Hypothesis
Po określeniu najbardziej prawdopodobnej hipotezy, należy ją zweryfikować a następnie przygotować plan naprawy danego problemu. Może być to rozwiązanie zarówno stałe jak i tymczasowe.
Problem
Resolution
Podjęcie próby naprawy występującego problemu.
Popularne metody Troubleshooting-u
Metody rozwiązywania problemów
The top-down method (7 ->1) – Metoda rozpoczynająca proces troubleshooting-u od warstwy aplikacji (7) a kończąca na warstwie fizycznej (1).
The bottom-up method (1 ->7) – Metoda rozpoczynająca proces troubleshooting-u od warstwy fizycznej (1) a kończąca na warstwie aplikacji (7).
The divide-and-conquer method (1 <- 3 -> 7) – Metoda rozpoczynająca proces troubleshooting-u od warstwy trzeciej (3) a następnie idąca w górę do warstwy aplikacji (7) bądź w dół od warstwy fizycznej (1), w zależności od osiągniętego rezultatu. Jeżeli np. komenda Ping nie osiągnie zamierzonego celu, administrator uzna że błąd dotyczy warstw niższych.
Following the traffic path – Metoda rozpoczynająca proces troubleshooting-u od weryfikacji połączenia pomiędzy hostem zgłaszającym problem a najbliższym urządzeniem sieciowych. W kolejnym kroku weryfikacji podlega następne urządzenie stojące na drodze od hosta do celu danej transmisji.
Comparing configurations – Metoda rozpoczynająca proces troubleshooting-u od porównania konfiguracji bieżącej z ostatnią znaną i wypełni sprawną konfiguracją.
Component swapping – Metoda rozpoczynająca proces troubleshooting-u od wymiany komponentów. Przykładowo wymianie takiej może podlegać kabel Ethernet-owy, pojedynczy moduł rutera bądź całe urządzenie sieciowe.
Konserwacja sieci (Maintenance)
Definicja procesu konserwacji sieci
Proces konserwacji pozwala utrzymać sieć w stanie spełniającym wymogi założeń biznesowych, związanych z funkcjonowaniem i dostępnością sieci. Przykładowe czynności zaliczane do procesu konserwacji są następujące:
Instalacja i konfiguracja urządzeń sieciowych.
Rozwiązywanie problemów (Troubleshooting).
Monitorowanie i zwiększanie wydajności sieci.
Tworzenie dokumentacji sieci jak i zmian w niej dokonywanych.
Sprawdzanie sieci pod kontem zgodności z prawem oraz standardami firmowymi.
Zabezpieczanie sieci przed zewnętrznymi jak i wewnętrznymi zagrożeniami.
Tworzenie kopi zapasowych.
Proaktywne (Proactive) & Reaktywne (Reactive) podejście do konserwacji
sieci
Podejście do procesu konserwacji sieci może być podjęte na dwa sposoby:
Interrupt-driven Tasks – Obejmuje proces rozwiązywania problemów w miarę ich zgłaszania.
Sructured Tasks – Obejmuje proces rozwiązywania problemów w sposób zaplanowany. Dzięki czemu możliwe staje się zapobieganie awariom, zanim staną się one poważnym problemem dla całej infrastruktury. Podejście to odnosi się również do planowanych inwestycji, w wymianę istniejącego jak i zakup nowego sprzętu oraz oprogramowania.
W celu uproszczenia procesu konserwacji sieci, stworzono wiele ustandaryzowanych procedur takich jak:
Poszczególne elementy procesu konserwacji sieci wyglądają następująco:
Fault Management – Za pomocą narzędzi monitorujących jak i zbierających dane na temat stanu infrastruktury sieciowej, nadzoruje czy utylizacja urządzeń oraz przepustowość linków nie przekracza dopuszczalnej normy.
Configuration Management – Wymaga ciągłej aktualizacji zmian zachodzących w infrastrukturze sieciowej związanych z wymianą urządzeń bądź ich oprogramowania. Proces ten odnosi się również do bieżącej aktualizacji narzędzi monitorujących i zbierających dane na temat stanu infrastruktury sieciowej.
Accounting Management– Nadzorowanie zmian zachodzących w infrastrukturze sieciowej.
Performance Management – Monitorowanie przepustowości połączeń lokalnych LAN oraz zewnętrznych WAN, z uwzględnieniem implementacji jak i nadzorowania funkcji kolejkowania QoS.
Security Management – Wdrażanie jak i monitorowanie zapór ogniowych (Firewall), wirtualnych połączeń prywatnych VPN, systemów prewencyjnych IPS, zabezpieczania dostępu za pomocą funkcji AAA czy nadzorowania polis bezpieczeństwa takich lak np. listy ACL.
Metody konserwacji sieci
Rutynowe zadania konserwacyjne
Rutynowe zadania konserwacyjne stanowią nierozłączną część każdej odpowiednio zaplanowanej infrastruktury sieciowej, są to zadania wykonywane regularnie co godzinie, dzień, tydzień, miesiąc czy rok bądź też nieregularne takie jak dodawanie nowych użytkowników. Przykładowe zadania związane z rutynową konserwacją mogą być następujące:
Configuration changes – Dodawanie nowych użytkowników, urządzeń bądź oprogramowania. Dokonywanie zmian związanych z relokacją obecnych zasobów (Użytkowników, urządzeń) wraz związaną z tym rekonfiguracją systemów.
Replacement of older or failed hardware – Wymiana starych bądź uszkodzonych urządzeń.
Scheduled backup – Tworzenie kopi zapasowych konfiguracji, logging-ów zebranych z urządzeń sieciowych.
Monitoring network performance – Monitorowanie jak i zbieranie informacji na temat utylizacji urządzeń oraz przepustowości linków. Co może uprościć proces troubleshooting-u jak i pomóc w planowaniu nowych inwestycji.
Planowanie zadań konserwacyjnych
Kto zatwierdza zmiany dokonywane w infrastrukturze sieciowej.
Jakie zadania powinny być wykonywane jedynie w oknie czasowym przeznaczonym na zadania konserwacyjne.
Jakie procedury obowiązują podczas przeprowadzania zadań konserwacyjnych.
Jakie kryteria określają sukces bądź porażkę przeprowadzonych zadań konserwacyjnych.
W jaki sposób będą dokumentowane zmiany zachodzące w infrastrukturze sieciowej.
Jakie narzędzia pozwolą przywrócić poprzednią działającą konfiguracje w przypadku niepowodzenia w wdrażaniu nowych rozwiązań bądź aktualizacji obecnej infrastruktury sieciowej.
Prowadzenie dokumentacji sieciowej
Dokumentacja infrastruktury sieciowej
Tworzenie jak i utrzymywanie bieżącej dokumentacji infrastruktury sieciowej ułatwia proces troubleshooting-u, ponieważ administrator w łatwy sposób może rozeznać się w konfiguracji sieci porównując stan obecny z założeniami.
Dokumentacja infrastruktury sieciowej może zwierać fizyczną (Physical) i logiczną (Logical) topologię sieci, konfiguracje poszczególnych urządzeń, procedury zmiany bieżącej konfiguracji, kontakt z osobami odpowiedzialnymi za daną część sieci czy wykaz dokonywanych zmian. Podsumowując dokumentacja infrastruktury sieciowej może zwierać:
Topologię logiczną (Logical Topology).
Topologię fizyczną (Physical Topology).
Listę połączeń pomiędzy urządzeniami.
Inwentarz urządzeń sieciowych.
Spis adresacji sieciowej.
Informacje na temat konfiguracji.
Plany założeń infrastruktury sieciowej.
Przywracanie sieci po awarii
Przywrócenie pełnej funkcjonalności sieci po awarii urządzeń sieciowych, może być dokonane za pomocą:
Z duplikowanego wyposażenia (Hardware) znajdującego się w lokalnym magazynie.
Zapasowego oprogramowania przetrzymywanego na lokalnych serwerach.
Kopi zapasowych (Konfiguracji) pobranych z urządzeń sieciowych.
Włącza śledzenie ruchu sieciowego na danym porcie: * host adres-IP– Filtruje dane wyjściowe pod kontem wskazanego adresu IP. * net adres-IP/prefix – Filtruje dane wyjściowe pod kontem wskazanej sieci. * port port – Filtruje dane wyjściowe pod kontem wskazanego portu. * portrange zakres-portów – Filtruje dane wyjściowe pod kontem wskazanych portów [portrange 20-34]. * src {adres-IP / port port}– Filtruje dane wyjściowe pod kontem wskazanego adresu źródłowego lub portu. * dst {adres-IP / port port}– Filtruje dane wyjściowe pod kontem wskazanego adresu docelowego lub portu. * protocol – Filtruje dane wyjściowe pod kontem wskazanego protokołu (IP, ICMP, UDP, TCP…). * {less liczba / greater liczba / <=liczba}– Wyświetla dane mniejsze, równe bądź większe od wskazanej liczby. *-i{nazwa-interfejsu/ any}– Określa śledzony interfejs sieciowy. * -D – Wyświetla listę dostępnych interfejsów sieciowych. *-cliczba – Wyświetla określoną ilość pakietów. *-Eklucz – Deszyfruje i wyświetla ruch IPSec z użyciem podanego klucza. *-q – Zmniejsza ilość wyświetlanych danych. *-e– Wyświetla docelowe i źródłowe adresy MAC. * -wplik – Zapisuje dane do wskazanego pliku. *-rplik – Wyświetla dane zawarte w wskazanym pliku. * {and / &&}– Łączy pojedyncze komendy w większą całość [tcpdump src port 20 && stc host 192.168.20.1]. * and {not / !}– Nie wyświetla wskazanej zawartości [tcpdump src port 20 && ! icmp].
Wyświetla wszystkie dostępne pule adresów DHCP, skonfigurowanych na wskazanym serwerze Windows Server. Opcjonalna pod komenda “FL” wyświetla bardziej szczegółowe informacje, dotyczące dostępnych puli DHCP.
Wyświetla wskazaną w komendzie pulę adresów DHCP. Opcjonalna pod komenda “FL” wyświetla bardziej szczegółowe informacje, dotyczące wskazanej puli DHCP.
#show
interfaces interfejs pruning– Wyświetla stan
funkcji pruning
dla sieci VLAN na danym interfejsie.
#show
interface interfejs trunk –
Wyświetla konfigurację interfejsu pod kontem połączenia Trunk-owego. Komenda
składa się z trzech pozycji kolejno wyświetlających następujące informacje:
Vlans allowed on trunk – Wyświetla sieci VLAN
dozwolone do ruchu na określonym połączeniu.
Vlans allowed and active in
management domain
– Wyświetla tylko aktywne sieci VLAN dozwolone do ruchu na określonym
połączeniu trunk-owym.
Vlans in spanning tree
Forwarding state and not pruned – Wyświetla nieblokowane przez protokół STP, sieci VLAN dla
określonego połączenia trunk-owego.
#show
interface interfejs switchport –
Wyświetla konfigurację interfejsu pod kontem sieci VLAN (Access, Trunk).
#show
interface status – Wyświetla informacje o statusie (Up) interfejsu
oraz o trybie pracy (speed i duplex).
# show interfaces status
Port Name Status Vlan Duplex Speed Type
Gi0/0 OOB management connected
routed a-full auto
RJ45
Gi0/1 to Switch2 connected trunk
a-full auto RJ45
Gi0/2 to
Switch2 connected trunk
a-full auto RJ45
Gi0/3 to Router1 connected 2 a-full auto
RJ45
Gi1/0 to Switch3 connected trunk
a-full auto RJ45
Gi1/1 to
Switch3 connected trunk
a-full auto RJ45
a- (np. a-full) – Oznacza, że
połączenie zostało negocjowane automatycznie (Autonegotiation).
! Istnieje możliwość, że stan interfejsu (speed,
duplex) będzie określony jako nauczony dynamicznie (a-half, a-100), chodź w
rzeczywistości auto negocjacja zawiodła. Przykładowo, kiedy jeden z
przełączników działa w trybie auto negocjacji natomiast drugi ma statycznie
ustawione wartości (speed, duplex).
!
Po mimo wadliwych ustawień stanu Duplex, przełącznik może wyświetlać status
interfejsu jako up/up, chodź w rzeczywistości połączenie nie będzie działać
poprawnie.
#show
interface interfejs – Wyświetla
szczegółowe informacje o określonym interfejsie sieciowym.
# show interfaces gigabitEthernet 0/1
GigabitEthernet0/1 is up, line
protocol is up (connected)
Hardware is iGbE, address is fa16.3e14.65c8 (bia fa16.3e14.65c8)
Description: to Switch2
MTU 1500 bytes, BW 1000000 Kbit/sec, DLY 10 usec,
reliability 255/255, txload 1/255,
rxload 1/255
Encapsulation ARPA, loopback not set
Keepalive set (10 sec)
Auto Duplex, Auto Speed, link type is auto, media type is unknown
media type
output flow-control is unsupported, input flow-control is unsupported
Full-duplex, Auto-speed, link type is auto, media type is RJ45
input flow-control is off, output flow-control is unsupported
ARP type: ARPA, ARP Timeout 04:00:00
Last input 00:00:28, output 00:00:00, output hang never
Last clearing of “show interface” counters never
Input queue: 0/2000/0/0 (size/max/drops/flushes); Total output drops:
0
Queueing strategy: fifo
Output queue: 0/0 (size/max)
5 minute input rate 0 bits/sec, 0 packets/sec
5 minute output rate 0 bits/sec, 0 packets/sec
9250 packets input, 518775 bytes, 0 no
buffer
Received 9249 broadcasts (9249
multicasts)
0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun,
0 ignored
0 watchdog, 9249 multicast, 0 pause
input
423565 packets output, 27079687 bytes, 0
underruns
0 output errors, 0 collisions, 8
interface resets
0 unknown protocol drops
0 babbles, 0 late collision, 0 deferred
1 lost carrier, 0 no carrier, 0 pause
output
0 output buffer failures, 0 output
buffers swapped out
Runts
– Ilość ramek Ethernet-owych niespełniających minimalnej wielkości
(64 bajty).
Giants
– Ilość ramek Ethernet-owych przekraczających maksymalną wielkość
(1518 bajty).
Input
Errors – Ilość otrzymanych
błędnych ramek Ethernet-owych.
CRC
– Ilość ramek Ethernet-owych,
które nie przeszły testu CRC.
Frame
– Ilość ramek Ethernet-owych,
które zawierają błędną końcówkę lub zły format.
Packet
Output – Ogólna liczba
przetworzonych ramek Ethernet-owych.
Output
Errors – Ogólna liczba przetworzonych błędnych ramek Ethernet-owych.
Late
Collisions – Liczba kolizji, które wystąpiły po otrzymaniu 64 bitów
ramki Ethernet-owej.
Collisions
– Liczba kolizji.
Komendy SHOW MAC
#show
mac address-table – Wyświetla wszystkie adresy MAC zapisane na
urządzeniu.
#show
mac address-table static –Wyświetla statycznie
dodane adresy MAC.
#show
mac address-table address adres-MAC –Wyświetla określony
adres MAC.
#show
mac address-table count [vlan
VLAN-id]–Wyświetla ilość adresów MAC przypisanych
do sieci VLAN.
#show
mac address-table aging-time [vlan
VLAN-id]– Wyświetla czas
przechowywania adresów MAC.
#show
mac address-table interface interfejs – Wyświetla adresy
MAC przypisane do określonego interfejsu.
Komendy SHOW Err-disabled
# show interfaces interfejs status – Wyświetla podstawowe informacje na temat
danego interfejsu sieciowego, w tym status, sieć VLAN, typ interfejsu, tryb
pracy speed oraz duplex.
# show interfaces interfejs status err-disabled – Wyświetla informacje na temat stanu
err-disabled względem interfejsu.
Komendy Show (Warstwa trzecia)
Komendy SHOW (Switching)
# Komendy show
dotyczące xxx:
# show – Wyświetla
# show – Wyświetla
# show – Wyświetla
# Komendy show
dotyczące xxx:
# show – Wyświetla
# show – Wyświetla
# show – Wyświetla
Komendy SHOW (Routing)
# Komendy show
dotyczące xxx:
# show – Wyświetla
# show – Wyświetla
# show – Wyświetla
# show – Wyświetla
# Komendy show
dotyczące xxx:
# show – Wyświetla
# show – Wyświetla
# show – Wyświetla
Komendy Clear
Komendy Clear (Switching)
# Komendy clear
dotyczące xxx:
# clear – Czyści
# clear – Czyści
# clear – Czyści
# clear – Czyści
# Komendy clear
dotyczące xxx:
# clear – Czyści
# clear – Czyści
# clear – Czyści
Komendy Clear (Routing)
# Komendy clear
dotyczące xxx:
# clear – Czyści
# clear – Czyści
# clear – Czyści
# clear – Czyści
# Komendy clear
dotyczące xxx:
# clear – Czyści
# clear – Czyści
# clear – Czyści
Komendy Debug
!
Aktywując komendę Debug, co do której istnieje podejrzenie że wyświetli
ona dużą ilość komunikatów. Należy używać linii VTY, ponieważ połączenie
konsolowe ma pierwszeństwo nad innymi operacjami rutera, co mogło by
doprowadzić do zawieszenia systemu Cisco IOS.
Projektowanie bezpiecznej sieci jest zadaniem bardzo trudnym, ponieważ różnorodność współczesnych zagrożeń zwiększa się z każdym dniem. Wymuszając na informatykach posiadanie większej wiedzy związanej z metodami ochrony informacji oraz infrastruktury sieciowej. W czym pomagają im pozarządowe organizacje, pracujące nad badaniem i rozwojem nowych zabezpieczeń. Dzięki wydawanym normą kształtują one standardy znacząco zwiększające poziom bezpieczeństwa firm, które się do nich stosują. Jedną z najważniejszych organizacji jest Międzynarodowa Organizacja Normalizacyjna ISO (z ang. International Organization for Standardization) powstała w 1946 roku w Londynie. Publikuje ona normy zawierające między innymi standardy projektowania oraz wdrażania bezpiecznych sieci.
Pojęcie bezpieczeństwa w odniesieniu do informatyki istniało już od wielu dziesięcioleci jednak dopiero rozpowszechnienie Internetu uczyniło tą kwestie tak ważną jak jest obecnie. W przypadku starych niepołączonych ze sobą systemów, istniało bardzo małe prawdopodobieństwo zainfekowania wirusem komputerowym, ponieważ dane były przenoszone dyskietkami a każda interakcja ze światem zewnętrznym wymagała fizycznego kontaktu. Jednak współczesne sieci LAN i WAN pozwalają hackerom na łatwe odnajdywanie i zarażanie nowych ofiar, w czym często pomagają sami użytkownicy, zaniedbujący poziom bezpieczeństwa swoich urządzeń, w szczególności, jeśli należą one do firmy, w której pracują. Dlatego administrator projektujący sieć musi skrupulatnie przeanalizować każdy element swojego projektu, nieustanie szukając nowych zagrożeń i luk w zabezpieczeniach. Etap projektowania testowania i sprawdzania stanu sieci jest cykliczny i powinien być powtarzany przez cały okres istnienia sieci. Ponieważ brak skrupulatnego sprawdzania może doprowadzić do włamania się osób niepowołanych, a tym samym uszkodzenia sieci lub wycieku cennych danych. Dla ułatwienia pracy proces projektowania można podzielić na segmenty, z których każdy zajmuje się innym aspektem ułatwiając przygotowanie finalnej konfiguracji oraz udostępniającym administratorom odpowiednie środki do późniejszego dbania o jej stan. Mierzenie poziomu bezpieczeństwa, przeprowadzenie analizy ryzyka czy przygotowanie polityki bezpieczeństwa jest częścią procesu zwanego zarządzaniem ryzykiem.
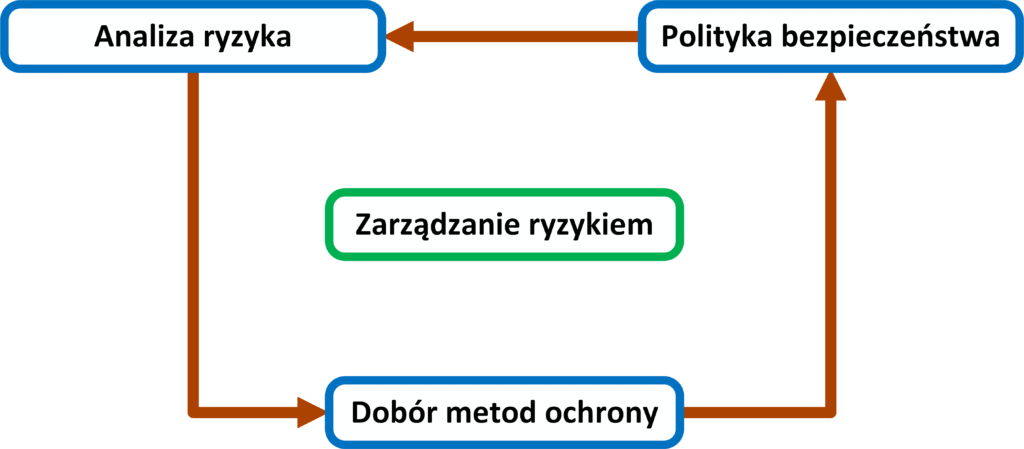
Zarządzanie ryzykiem
Proces zarządzania ryzykiem składa się z etapów zajmujących się wykrywaniem, monitorowaniem i analizowaniem zagrożeń oraz szukaniem metod im przeciwdziałających. Jest to proces powtarzalny, dlatego po pierwszym wdrożeniu należy sukcesywnie sprawdzać jego efektywność, systematycznie uaktualniając informacje o obecnym stanie infrastruktury firmowej. Przede wszystkim należy pamiętać o prostej zasadzie mówiącej, że dla informatyka stanie w miejscu jest równoznaczne z cofaniem się, dlatego tak ważne jest okresowe badanie wszystkich elementów zabezpieczeń sieciowych oraz systematyczne doszkalanie pracowników pod kontem nowych rozwiązań technicznych dotyczących bezpieczeństwa.
Zarządzanie składa się z etapów, z których najważniejszymi są: analiza ryzyka, dobór metody ochrony czy przygotowanie polityki bezpieczeństwa, jako końcowego dokumentu zawierającego wszystkie procedury firmy, związane z ochroną sieci przed atakami zewnętrznymi jak i wewnętrznymi oraz metodami im przeciwdziałającymi. Analiza zagrożeń jest etapem tworzenia spisu wszystkich urządzeń i usług sieciowych wraz z przypisanymi do nich zagrożeniami, jakie mogą wpłynąć na ich prawidłową prace. Odpowiada na pytania co, gdzie, po co oraz dlaczego ma chronić. Dzięki uzyskanym informacją jesteśmy w stanie zdecydować jakie kroki należy podjąć w celu eliminacji występujących zagrożeń. Następnie w procesie dobierania metody ochrony, zostaje wyłoniony jak najbardziej efektywny a jednocześnie oszczędny sposób przeciwdziałania zagrożeniom. Przykładowo jednym z rozwiązań może być zakup oprogramowania antywirusowego, jeśli zagrożeniem jest połączenie z Internetem. W innym przypadku ochroną przed uszkodzeniem fizycznym, może być zastosowanie nadmiarowych połączeń lub dodatkowych urządzeń, dzięki czemu uszkodzenie jednego z nich nie spowoduje przerwy w łączności z siecią. Ostatnim elementem procesu jest końcowe spisanie polityki bezpieczeństwa jako zbioru zasad, reguł oraz wytycznych obowiązujących w firmie, zarówno podczas planowania i wdrażania infrastruktury sieciowej jak i dalszego jej funkcjonowania. Po zakończeniu pracy oczywiści nie można zapomnieć o systematycznej obserwacji zmieniającego się środowiska wewnętrznego oraz zewnętrznego. Bowiem administrator nigdy nie może uznać swojej sieci za stuprocentowo bezpieczną, zapominając tym samym o systematycznym sprawdzaniu poziomu jej zabezpieczeń.
Zarządzanie ryzykiem
Analiza ryzyka
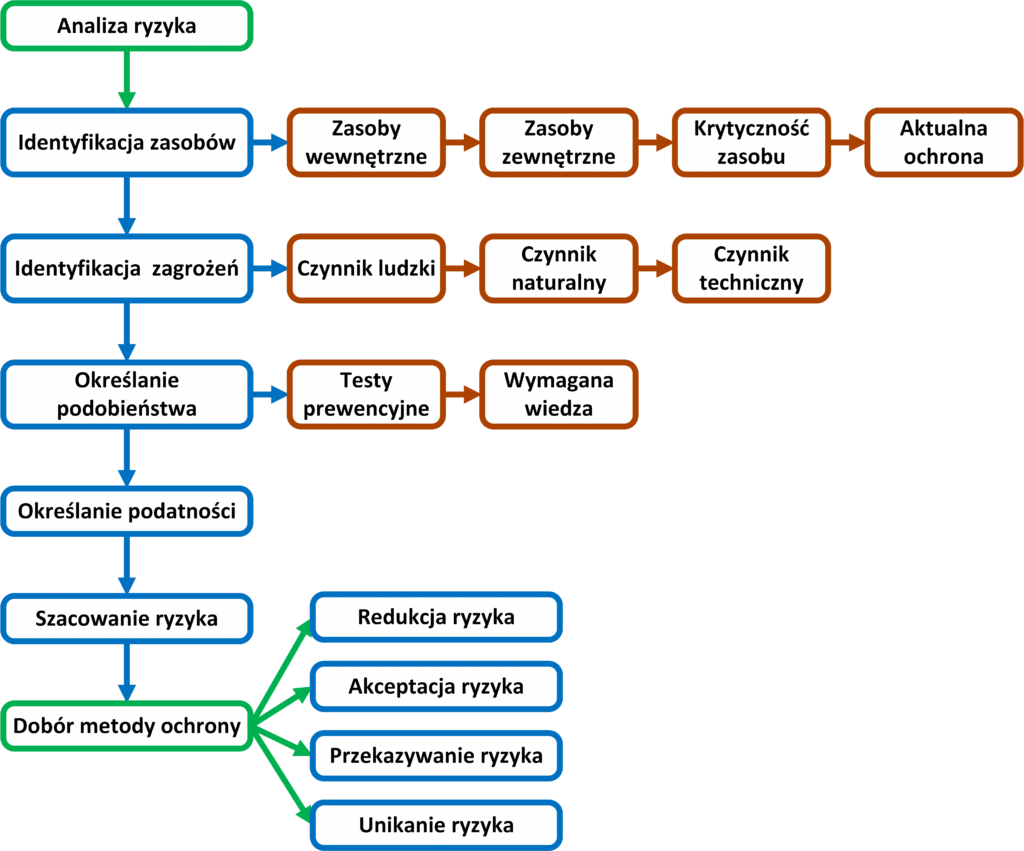
Analiza ryzyka jest etapem uświadamiania sobie, jakiego rodzaju zagrożenia i w jakim stopniu, mogą wpłynąć na prawidłowe funkcjonowanie sieci. Do pełnego zrozumienia tej koncepcji, należy zapoznać się z znaczeniem podstawowych pojęć funkcjonujących w normie ISO/IEC 27001:2005. Pierwsze pojęcie aktywów dotyczy wszystkich elementów znajdujących się firmie, posiadających wartość materialną lub strategiczną. Drugie zasobów jako miejsca przeznaczonego do przechowywania aktywów, przykładowo różne systemy informatyczne zainstalowane na serwerze będą aktywami natomiast sam serwer będzie zasobem. Ostatnie pojęcie dotyczy bezpieczeństwa informacji, składającego się z trzech cech: poufności, dzięki czemu informacja znana jest jedynie nadawcy i odbiorcy, integralności sprawdzającej czy wiadomość nie była modyfikowana przez osobę do tego nieuprawnioną oraz dostępności dbającej o kontrolowany dostęp do informacji. Proces analizowania ryzyka składa się z pięciu etapów, z których każdy jest konieczny do osiągnięcia skutecznej ochrony.
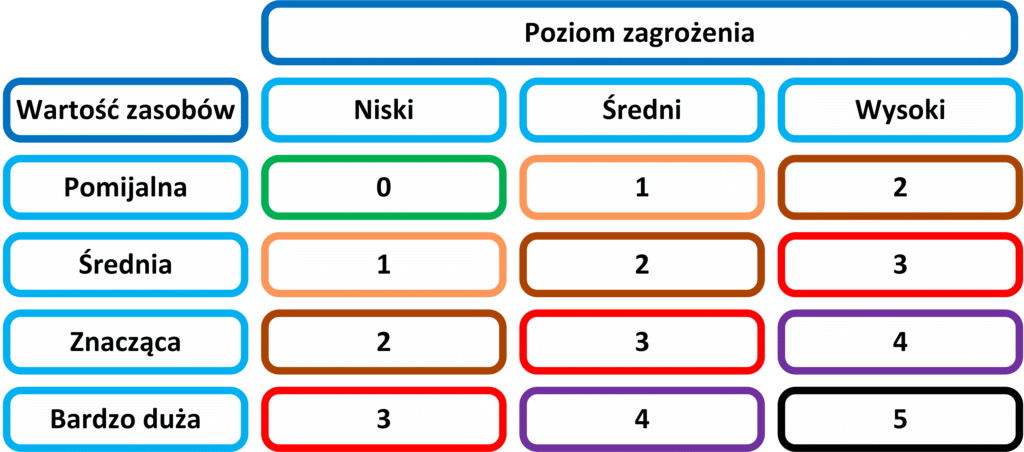
Pierwszy etap identyfikacji, polega na przeprowadzeniu inwentaryzacji wszystkich zasobów sieciowych firmy oraz ocenie ich znaczenia. Ponieważ bez znajomości urządzeń, jakie posiadamy nie jesteśmy w stanie o nie zadbać. Podczas określania wartości poszczególnych zasobów, należy uwzględnić ich wartość strategiczną, jak i rozważyć wpływ, jaki będzie miała ich utrata na funkcjonowanie całej firmy. Im większy wpływ tym większa wartość zasobu, oceniana przeważnie przez pryzmat wartości materialnej (finansowej). Oczywiście istnieją zasoby takie jak wizerunek czy opinia o firmie, których nie da się prosto przeliczyć na pieniądze, dlatego wartość poszczególnych zasobów można oceniać porównując je między sobą zgodnie z następującymi wartościami:
Bardzo duża – Utrata lub uszkodzenie zasobu uniemożliwia funkcjonowanie firmy.
Znacząca– Utrata lub uszkodzenie zasobu ma wpływ na funkcjonowanie firmy.
Średnia– Utrata lub uszkodzenie zasobu powoduje utrudnienia w normalnym funkcjonowaniu firmy.
Pomijalna– Utrata lub uszkodzenie zasobu nie ma wpływ na funkcjonowanie firmy.
Analiza ryzyka
Opisując poszczególne zasoby, należy określić, czy należą one do lokalnej infrastruktury, nad którą sprawujemy kontrole, mając dostęp do pełnej konfiguracji, czy jest to element sieci utrzymywany dzięki współpracy z innymi firmami, na zasadzie outsourcingu jak zewnętrze centra danych lub jako ogólnodostępne serwery poczty czy DNS. Inną ważną informacją mogą być dane o już istniejących zabezpieczeniach, jeśli przeprowadzamy proces analizy w funkcjonującej firmie albo wykonujemy go ponownie po przeprowadzeniu dużych zmian w infrastrukturze.
Etap drugi identyfikuje jakiego rodzaju niebezpieczeństwa mogą zagrozić poszczególnym zasobom naszej firmy, dzięki czemu w następnym punkcie będziemy mogli określić poziom zagrożenia dla danego zasobu. Należy wziąć pod uwagę możliwość wystąpienia nadzwyczajnych zagrożeń naturalnych (powodzi, trzęsienia ziemi), czynnika ludzkiego w postaci pracowników firmy lub osób zewnętrznych czy uszkodzeń fizycznych wynikających z długotrwałej eksploracji sprzętu sieciowego. Należy również określić przyczyny powstawania powyższych sytuacji (np. zagrożenia spowodowane przez ludzi mogą wynikać z ataku hackerskiego) jak i szkód, jakie mogą wyrządzić (np. sparaliżowanie usług serwera). Inną ważną informacją jaka powinna się znaleźć w tabeli identyfikującej zagrożenia, jest wpływ na utratę poufności, integralności czy dostępności danych. Przykładowo zgubienie przez administratora pamięci USB może wpłynąć na poufność przechowywanych na niej informacji. Istnieję również przypadki, w których zwiększony poziom dostępności jest osiągany kosztem poufności, na przykład ilość zasobów, na których przechowujemy aktywa firmowe, ma znaczący wpływ na poziom ich bezpieczeństwa. Czym większa liczba oddalonych od siebie lokalizacji przetwarzających dane tym większe zagrożenie utraty poufności, wiążącej się z ryzykiem ujawnienia wrażliwych informacji. Z drugiej strony zwiększenie ilości miejsc przechowujących dane, wpływa na podwyższony poziom ich dostępności. W takiej sytuacji należy podjąć decyzje o tym co jest ważniejsze z punktu widzenia firmy, a tym samym czy warto podjąć ryzyko wynikające z możliwych do wystąpienia zagrożeń. Niezależnie od wielkości sieci, którą opisujemy zawsze można skorzystać z dodatkowej pomocy w postaci przykładowych list zawierających najczęściej występujące zagrożenia przyporządkowane do konkretnych zasobów, dzięki czemu nasza analiza wzbogaci się o opcje które sami mogliśmy pominąć bądź niemieliśmy o nich wiedzy. Przede wszystkim należy pamiętać, aby wszystkie przypisane do zasobów zagrożenia były jak najbardziej realnymi scenariuszami, dzięki czemu uzyskamy aktualne i miarodajne wyniki.
Po identyfikacji zasobów (etap pierwszy) i przyporządkowaniu do nich możliwych zagrożeń (etap drugi) należy określić jak realne są to niebezpieczeństwa oraz jakie jest prawdopodobieństwo ich wystąpienia. Przykładowo awaria zasilania jest bardziej prawdopodobna niż sunnami czy trzęsienie ziemi w środkowej Polsce. Dodatkową praktyką stosowaną przez wiele firm jest przeprowadzanie testów prewencyjnych, podczas których następuje symulacja ataku na infrastrukturę IT. Dzięki czemu staje się możliwe wykrycie luk w zabezpieczeniach sieci. Tak samo jak w przypadku identyfikacji zasobów, tak i szacowaniu ryzyka możemy określić prawdopodobieństwo wystąpienia zagrożenia przy pomocy określonych wartości wykorzystywanych w metodzie jakościowej lub zastosować wyliczenia oparte na konkretnych liczbach (związanych z wartością finansową zasobu) przy zastosowaniu metody ilościowej.
Poziom szacowania zagrożenia metoda jakościową:
Wysoki– Występuje często (np. raz w miesiącu), regularnie.
Średni– Występuje rzadko (np. raz w roku), nieregularnie.
Niski – Nie wystąpiło w przeciągu roku.
Po określeniu, co chcemy chronić, dlaczego chcemy to robić i przed czym to robimy, należy ustalić, jakie są słabe punkty zasobów, przez co stają się podatne na ataki czy inne zagrożenia. Przykładowo w sytuacji, gdy firma łączy się pomiędzy swoimi oddziałami za pomocą sieci publicznej, możemy stwierdzić, że przesyłane przez nią wrażliwe informacje (aktywa) mogą zostać odczytane (zagrożone) przez osobę niepowołaną, dlatego należy dodatkowo zabezpieczyć urządzenia (zasoby) uczestniczące w komunikacji. Pamiętając, że na tym etapie określamy jedynie właściwości zasobów, które mogą zostać wykorzystane podczas ataku a nie metody im zapobiegające.
Ostatni etap polega na oszacowaniu istniejącego ryzyka dla poszczególnych aktywów, zasobów względem ich wartości strategicznej, na podstawie przeprowadzonej analizy, przed zastosowaniem środków zabezpieczających. W tym celu tworzymy tabelę opartą o dane zabrane w poprzednich punktach, uzyskując tym samym liczbową wartość istniejącego ryzyka, wystąpienia zagrożenia dla rozpatrywanych aktywów lub zasobów. Dodatkową praktyką ułatwiającą późniejsze wprowadzanych zmian w poziomie zabezpieczeń firmy, jest określenie ryzyka akceptowalnego. Stanowi ono poziom określający w jakich przypadkach należy niezwłocznie zająć się istniejącym zagrożeniem a w jakim interwencja nie jest pilna i może być odroczona w czasie. Przykładowo w poniższej tabeli granicą ryzyka akceptowalnego może być poziom pomiędzy numerem drugim a trzecim.
Szacowanie ryzyka
Dobór metod ochrony
Po przeprowadzeniu procesu analizy ryzyka, należy wdrożyć metody minimalizujące możliwość wystąpienia określonych zagrożeń. Szczególnie w sytuacji, gdy przekraczają one ustaloną wartość ryzyka akceptowalnego. Istnieją cztery wzajemnie wykluczające się podejścia, do sposobu podejmowania decyzji o ich redukcji. Każde należy rozpatrzyć indywidualne wzglądem poszczególnych aktywów lub zasobów:
Redukcja ryzyka – Polega na wdrożeniu środków, mających zredukować ryzyko wystąpienia zagrożenia. Przykładowo po ustaleniu, że serwer może być zagrożony atakiem hackerskim i jest to bardzo prawdopodobne, a jednocześnie posiadanie przez firmę serwera konieczne, należy wprowadzić metody zabezpieczające, niezależnie od ich kosztów. Może być to zakup np. zapory ogniowej zapewniającej ochronę przed atakami czy urządzenia IPS przeznaczonego do analizowania ruchu sieciowego.
Akceptacja ryzyka – W przypadku, gdy, cena redukcji zagrożenia jest zbyt wysoka a niebezpieczeństwo wystąpienia niskie, można zaakceptować możliwość jego zajścia bez podejmowania kroków mających wyeliminować możliwość jego wystąpienia.
Przekazywania ryzyka– Może przybrać formę ubezpieczenia czy „outsourcing-u”[1], przerzucając ryzyko wystąpienia zagrożenia na inną firmę, przeważnie dysponującą kadrą bardziej wykwalifikowanych i doświadczonych informatyków.
Uniknięcieryzyka – W przypadku istnienia zbyt dużego zagrożenia, względem niskich korzyści wynikających z użytkowania danego aktywu, firma może podjąć decyzje o zaprzestaniu dalszego używania danego elementu infrastruktury, w celu całkowitego wykluczenia możliwość wystąpienia zagrożenia.
Polityka bezpieczeństwa
Po wybraniu metod przeciwdziałających zagrożeniom, poprzedzonych analizą ryzyka, następuje etap spisania polityki bezpieczeństwa. Zbioru zasad, reguł i wytycznych, którymi administrator kieruje się przy tworzeniu i rozbudowie sieci. Jego treść będzie pomocna zarówno przy konfiguracji i wdrażaniu całej infrastruktury, jak i przez cały czas funkcjonowania firmy. Dlatego musi zawierać informacje o zasadach przetwarzania i dostępu do danych, codziennych zachowań pracowników pod względem bezpieczeństwa oraz procesu przyznawania dostępu do zasobów i ochrony przed wyciekiem informacji. Istnieje powiedzenie „Człowiek najsłabszym elementem bezpieczeństwa IT”, dlatego należy pamiętać, że zbyt rozbudowane środki ostrożności, szczególnie opisane technicznym językiem, mogą spowolnić pracę lub wręcz zniechęcić pracowników do ich stosowania. Konieczne jest więc, ich uświadamianie poprzez kursy instruktażowe mające na celu wyjaśnienie zasad oraz przyczyn istnienia takiej polityki, dobrym rozwiązaniem są testy bezpieczeństwa sprawdzające reakcje pracowników na nietypowe prośby działu administracji np. z zapytaniem o podanie hasła i loginu w celach weryfikacji danych, czego oczywiście nigdy nie powinni robić.
Bezpieczeństwo jest terminem interdyscyplinarnym, badanym i opisywanym przez wiele dziedzin nauki. Należą do nich historia, psychologia, socjologia, nauki prawne, politologia oraz wiele innych. Różnorodność dziedzin, zajmujących się tym zagadnieniem, pokazuje jak złożony i bogaty w definicje jest to termin. W podstawowym znaczeniu etymologicznym z języka łacińskiego, słowo bezpieczeństwo „securitas” składa się z dwóch członów: „sine” (bez) i „cura” (zmartwienie, strach, obawa), rozpatrując bezpieczeństwo, jako stan braku zmartwień, strachu i obaw. Natomiast słownik nauk społecznych UNESCO, autorstwa Daniela Lernera rozpatruje opisywane pojęcie następująco „W najbardziej dosłownym znaczeniu bezpieczeństwo jest właściwie identyczne z pewnością (safety) i oznacza brak zagrożenia (danger) fizycznego albo ochronę przed nim”. Należy zwrócić tu uwagę na nierozłączny element występujący w parze z rozpatrywanym pojęciem, a jest nim niebezpieczeństwo, będące przyczyną występowania stanu zagrożenia. Przed którym chcąc się chronić, dążąc do stanu własnego bezpieczeństwa. Jest to pragnienie zakorzenione w naszej psychice, dlatego jego spełnienie zapewnia nam dużo lepsze samopoczucie, umożliwiając prawidłowe funkcjonowanie w otaczającym nas świecie. Zaspokojenie obaw, co do naszego losu jest jednym z najważniejszych zadań, jakie stawia przed nami życie, dlatego tak ważne abyśmy umieli o nie zadbać. Szczególnie w czasach współczesnych, dynamika zmieniającego się świata wymaga od ludzi szybkiego dostosowania się do panujących zasad i unikania nowych zagrożeń. Dodatkowo rozwój technologii na zawsze zmienił pojęcie bezpieczeństwa dodając do niego wiele nowych zagadnień. Zagrożone obecnie jest nie tylko nasze zdrowie czy życie, ale również dane osobowe, poufne informacje czy pieniądze zmagazynowane w postaci zer i jedynek w każdym zakątku naszego globu. Informacja stała się na tyle znaczącą „walutą”, że wielkie mocarstwa zamiast walki o surowce, coraz częściej zwracają się w stronę informatyków, mogących wykraść dane o technologii przeciwnika baz narażania się na poniesienie straty własnych.